Expanded genetic code
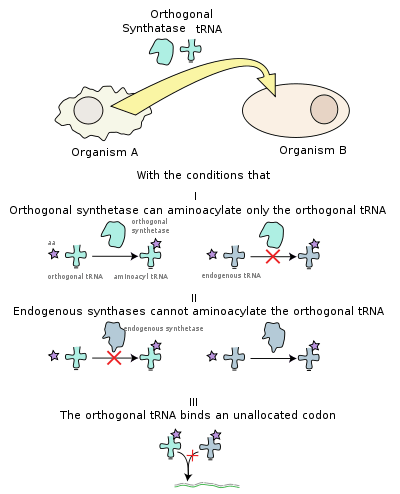
An expanded genetic code is an artificially modified genetic code in which one or more specific codons have been re-allocated to encode an amino acid that is not among the 20 encoded proteinogenic amino acids.[1]
The key prerequisites to expand the genetic code are:
- the non-standard amino acid to encode,
- an unused codon to adopt,
- a tRNA that recognises this codon, and
- a tRNA synthetase that recognises only that tRNA and only the non-standard amino acid.
Expanding the genetic code is an area of research of synthetic biology, an applied biological discipline whose goal is to engineer living systems for useful purposes. The genetic code expansion enriches the repertoire of useful tools available to science.
Introduction
Proteins are produced thanks to the translational system molecules, which decode the RNA messages into a string of amino acids. The translation of genetic information contained in messenger RNA (mRNA) into a protein is catalysed by ribosomes. Transfer RNAs (tRNA) are used as keys to decode the mRNA into its encoded polypeptide. The tRNA recognizes a specific three nucleotide codon in the mRNA with a complementary sequence called the anticodon on one of its loops. Each three nucleotide codon is translated into one of twenty naturally occurring amino acids.[2] There is at least one tRNA for any codon, and sometimes multiple codons code for the same amino acid. Many tRNAs are compatible with several codons. An enzyme called an aminoacyl tRNA synthetase covalently attaches the amino acid to the appropriate tRNA.[3] Most cells have a different synthetase for each amino acid (20 or more synthetases). On the other hand, some bacteria have fewer than 20 aminoacyl tRNA synthetases, and introduce the "missing" amino acid(s) by modification of a structurally related amino acid by an aminotransferase enzyme.[4] A feature exploited in the expansion of the genetic code is the fact the aminoacyl tRNA synthetase often does not recognize the anticodon, but another part of the tRNA, meaning that if the anticodon were to be mutated the encoding of that amino acid would change to a new codon. In the ribosome, the information in mRNA is translated into a specific amino acid when the mRNA codon matches with the complementary anticodon of a tRNA, and the attached amino acid is added onto a growing polypeptide chain. When it is released from the ribosome, the polypeptide chain folds into a functioning protein.[3]
In order to incorporate a novel amino acid into the genetic code several changes are required. First, for successful translation of a novel amino acid, the codon to which the novel amino acid is assigned cannot already code for one of the 20 natural amino acids. Usually a nonsense codon (stop codon) or a four-base codon are used.[2] Second, a novel pair of tRNA and aminoacyl tRNA synthetase are required, these are called the orthogonal set. The orthogonal set must not crosstalk with the endogenous tRNA and synthetase sets, while still being functionally compatible with the ribosome and other components of the translation apparatus. The active site of the synthetase is modified to accept only the novel amino acid. Most often, a library of mutant synthetases is screened for one which charges the tRNA with the desired amino acid. The synthetase is also modified to recognize only the orthogonal tRNA.[2] The tRNA synthetase pair is often engineered in other bacteria or eukaryotic cells.[5]
In this area of research, the 20 encoded proteinogenic amino acids are referred to as standard amino acids, or alternatively as natural or canonical amino acids, while the added amino acids are called non-standard amino acids (NSAAs), or unnatural amino acids (uAAs; term not used in papers dealing with natural non-proteinogenic amino acids, such as phosphoserine), or non-canonical amino acids.
Non-standard amino acids

The first element of the system is the amino acid that is added to the genetic code of an certain strain of organism.
Over 71 different NSAAs have been added to different strains of E. coli, yeast or mammalian cells.[6] Due to technical details (easier chemical synthesis of NSAAs, less crosstalk and easier evolution of the aminoacyl-tRNA synthase), the NSAAs are generally larger than standard amino acids and most often have a phenylalanine core but with a large variety of different substitutents. These allow a large repertoire of new functions, such as labelling (see figure), as a fluorescent reporter (e.g. dansylalanine)[7] or to produce translationally protein in E. coli with Eukaryotic post-translational modifications (e.g. phosphoserine, phosphothreonine, and phosphotyrosine).[6][8]
Unnatural amino acids incorporated into proteins include heavy atom containing amino acids to facilitate x-ray crystallographic studies; amino acids with novel steric/packing and electronic properties; photocrosslinking amino acids which can be used to probe protein-protein interactions in vitro or in vivo; keto, acetylene, azide, and boronate containing amino acids which can be used to selectively introduce a large number of biophysical probes, tags, and novel chemical functional groups into proteins in vitro or in vivo; redox active amino acids to probe and modulate electron transfer; photocaged and photoisomerizable amino acids to photoregulate biological processes; metal binding amino acids for catalysis and metal ion sensing; amino acids that contain fluorescent or infra-red active side chains to probe protein structure and dynamics; α-hydroxy acids and D-amino acids as probes of backbone conformation and hydrogen bonding interactions; and sulfated amino acids and mimetics of phosphorylated amino acids as probes of posttranslational modifications.[9][10][11][12]
Availability of the non-standard amino acid requires that the organism either import it from the medium or biosynthesised it. In the first case, the unnatural amino acid is first synthesised chemically in optically pure L-form.[13] It is then added to the growth medium of the cell.[6] Generally a library of compounds is tested to see which can be imported and incorporated, but often the various transport systems can handle unnatural amino acids with apolar side-chains. In the second case, a biosynthetic paths need to be engineered. One example is an E. coli strain that biosynthesizes a novel, previously unnatural amino acid (p-aminophenylalanine) from basic carbon sources and includes this amino acid in its genetic code.[12][14][15] Another example is the production of phosphoserine, which is a natural metabolite and as a consequence the pathway flux had to be altered to increase its production.[8]
Codon assignment
Another element of the system is a codon to allocate to the new amino acid.
A major problem for the genetic code expansion is that there are no free codons. The genetic code has a nonrandom layout that shows tell-tale signs of various phases of primordial evolution, however, it has since frozen into place and is near-universally conserved.[16] Nevertheless, some codons are rarer than others. In fact, in E. coli (and all organisms) the codon usage is not equal, but presents several rare codons (see table), the rarest being the amber stop codon (UAG).
| Codon | Amino acid | % abundance |
|---|---|---|
| UUU | Phe (F) | 1.9 |
| UUC | Phe (F) | 1.8 |
| UUA | Leu (L) | 1.0 |
| UUG | Leu (L) | 1.1 |
| CUU | Leu (L) | 1.0 |
| CUC | Leu (L) | 0.9 |
| CUA | Leu (L) | 0.3 |
| CUG | Leu (L) | 5.2 |
| AUU | Ile (I) | 2.7 |
| AUC | Ile (I) | 2.7 |
| AUA | Ile (I) | 0.4 |
| AUG | Met (M) | 2.6 |
| GUU | Val (V) | 2.0 |
| GUC | Val (V) | 1.4 |
| GUA | Val (V) | 1.2 |
| GUG | Val (V) | 2.4 |
| UCU | Ser (S) | 1.1 |
| UCC | Ser (S) | 1.0 |
| UCA | Ser (S) | 0.7 |
| UCG | Ser (S) | 0.8 |
| CCU | Pro (P) | 0.7 |
| CCC | Pro (P) | 0.4 |
| CCA | Pro (P) | 0.8 |
| CCG | Pro (P) | 2.4 |
| ACU | Thr (T) | 1.2 |
| ACC | Thr (T) | 2.4 |
| ACA | Thr (T) | 0.1 |
| ACG | Thr (T) | 1.3 |
| GCU | Ala (A) | 1.8 |
| GCC | Ala (A) | 2.3 |
| GCA | Ala (A) | 0.1 |
| GCG | Ala (A) | 3.2 |
| UAU | Tyr (Y) | 1.6 |
| UAC | Tyr (Y) | 1.4 |
| UAA | Stop | 0.2 |
| UAG | Stop | 0.03 |
| CAU | His (H) | 1.2 |
| CAC | His (H) | 1.1 |
| CAA | Gln (Q) | 1.3 |
| CAG | Gln (Q) | 2.9 |
| AAU | Asn (N) | 1.6 |
| AAC | Asn (N) | 2.6 |
| AAG | Lys (K) | 3.8 |
| AAA | Lys (K) | 1.2 |
| GAU | Asp (D) | 3.3 |
| GAC | Asp (D) | 2.3 |
| GAA | Glu (E) | 4.4 |
| GAG | Glu (E) | 1.9 |
| UGU | Cys (C) | 0.4 |
| UGC | Cys (C) | 0.6 |
| UGA | Stop | 0.01 |
| UGG | Trp (W) | 1.4 |
| CGU | Arg (R) | 2.4 |
| CGC | Arg (R) | 2.2 |
| CGA | Arg (R) | 0.3 |
| CGG | Arg (R) | 0.5 |
| AGU | Ser (S) | 0.7 |
| AGC | Ser (S) | 1.5 |
| AGA | Ser (S) | 0.2 |
| AGG | Ser (S) | 0.2 |
| GGU | Gly (G) | 2.8 |
| GGC | Gly (G) | 3.0 |
| GGC | Gly (G) | 0.7 |
| GGA | Gly (G) | 0.9 |
Amber codon suppression
The possibility of reassigning codons was realized by Normanly et al. in 1990, when a viable mutant strain of E. coli read through the UAG ("amber") stop codon.[18] This was possible thanks to the rarity of this codon and the fact that release factor 1 alone makes the amber codon terminate translation. Later, in the Schultz lab, the tRNATyr/tyrosyl-tRNA synthetase (TyrRS) from Methanococcus jannaschii, an archaebacterium,[2] was used to introduce a tyrosine instead of STOP, the default value of the amber codon.[19] This was possible because of the differences between the endogenous bacterial synthases and the orthologous archaeal synthase, which do not recognize each other. Subsequently, the group evolved the orthologonal tRNA/synthase pair to utilise the non-standard amino acid O-methyltyrosine.[20] This was followed by the larger naphthylalanine[21] and the photocrosslinking benzoylphenylalanine,[22] which proved the potential utility of the system.
The amber codon is the least used codon in Escherichia coli, but its highjacking results in a substantial loss of fitness. One study in fact found that there were at least 83 peptides majorly affected by the readthrough[23] Additionally, the labelling was incomplete. As a consequence, several strains have been made to reduce the fitness cost, including the removal of all amber codons from the genome. In most E. coli K-12 strains (viz. Escherichia coli (molecular biology) for strain pedigrees) there are 314 UAG stop codons. Consequently, a gargantuan amount of work has gone into the replacement of these. One approach pioneered by the group of Prof. George Church from Harvard, was dubbed MAGE in CAGE: this relied on a multiplex transformation and subsequent strain recombination to remove all UAG codons—the latter part presented a halting point in a first paper,[24] but was overcome. This resulted in the E. coli strain C321.ΔA, which lacks all UAG codons and RF1.[25] This allowed an experiment to be done with this strain to make it "addicted" to the amino acid biphenylalanine by evolving several key enzymes to require it structurally, therefore putting its expanded genetic code under positive selection.[26]
Rare sense codon reassignment
In addition to the amber codon, rare sense codons have also been considered for use. The AGG codon codes for arginine, but a strain has been successfully modified to make it code for 6-N-allyloxycarbonyl-lysine.[27] Another candidate is the AUA codon, which is unusual in that its respective tRNA has to differentiate against AUG that codes for methionine (primordially, isoleucine, hence its location). In order to do this, the AUA tRNA has a special base, lysidine. The deletion of the synthase (tilS) was possible thanks to the replacement of the native tRNA with that of Mycoplasma mobile (no lysidine). The reduced fitness is a first step towards pressuring the strain to loose all instances of AUA, allowing it to be used for genetic code expansion.[28]
Four base codons
Other approaches include the addition of extra base pairing or the use of orthologous ribosomes that accept in addition to the regular triplet genetic code, tRNAs with quadruple code.[29] This allowed the simultaneous usage of two unnatural amino acids, p-azidophenylalanine (AzPhe) and N6-[(2-propynyloxy)carbonyl]lysine (CAK), which cross-link with each other by Huisgen cycloaddition.[30]
tRNA/synthase pair
Another key element is the tRNA/synthase pair.
The orthologous set of synthetase and tRNA can be mutated and screened through directed evolution to charge the tRNA with a different, even novel, amino acid. Mutations to the plasmid containing the pair can be introduced by error-prone PCR or through degenerate primers for the synthetase's active site. Selection involves multiple rounds of a two-step process, where the plasmid is transferred into cells expressing chloramphenicol acetyl transferase with a premature amber codon. In the presence of toxic chloramphenicol and the non-natural amino acid, the surviving cells will have overridden the amber codon using the orthogonal tRNA aminoacylated with either the standard amino acids or the non-natural one. To remove the former, the plasmid is inserted into cells with a barnase gene (toxic) with a premature amber codon but without the non-natural amino acid, removing all the orthogonal synthases that do not specifically recognize the non-natural amino acid.[2] In addition to the recoding of the tRNA to a different codon, they can be mutated to recognize a four-base codon, allowing additional free coding options.[31] The non-natural amino acid, as a result, introduces diverse physicochemical and biological properties in order to be used as a tool to explore protein structure and function or to create novel or enhanced protein for practical purposes.
 Several methods for selecting the synthetase that accepts only the non-natural amino acid have been developed. One of which is by using a combination of positive and negative selection |
Orthogonal sets in E. coli
The orthogonal pairs of synthetase and tRNA that work for one organism may not work for another, as the synthetase may mis-aminoacylate endogenous tRNAs or the tRNA be mis-aminoacylated itself by an endogenous synthetase. As a result, the sets created to date differ between organisms.
- tRNATyr-TyrRS pair from the archaeon Methanococcus jannaschii
- tRNALys–LysRS pair from the archaeon Pyrococcus horikoshii[32]
- tRNAGlu–GluRS pair from Methanosarcina mazei[33]
- leucyl-tRNA synthetase from Methanobacterium thermoautotrophicum and a mutant leucyl tRNA derived from Halobacterium sp[34]
- tRNAAmber-PylRS pair from the archaeon Methanosarcina barkeri and Methanosarcina mazei
- tRNAAmber-3-Iodotyrosyl-tRNA synthetase (variant of aminoacyl-tRNA synthetase from Methanocaldococcus jannaschii)[35]
Orthogonal sets in yeast
- tRNATyr-TyrRS pair from Escherichia coli[36]
- tRNALeu–LeuRS pair from Escherichia coli[37]
- tRNAiMet from human and GlnRS from Escherichia coli[38]
- tRNAAmber-PylRS pair from the archaeon Methanosarcina barkeri and Methanosarcina mazei[39]
- tRNAAmber-4,5-dimethoxy-2-nitrobenzyl-cysteinyl-tRNA synthetase[40]
Orthogonal sets in mammalian cells
- tRNATyr-TyrRS pair from Bacillus stearothermophilus[41]
- modified tRNATrp-TrpRS pair from Bacillus subtilis trp[42]
- tRNALeu–LeuRS pair from Escherichia coli[43]
- tRNAAmber-PylRS pair from the archaeon Methanosarcina barkeri and Methanosarcina mazei
Applications
With an expanded genetic code, the unnatural amino acid can be genetically directed to any chosen site in the protein of interest. The high efficiency and fidelity of this process allows a better control of the placement of the modification compared to modifying the protein post-translationally, which, in general, will target all amino acids of the same type, such as the thiol group of cysteine and the amino group of lysine.[44] Also, an expanded genetic code allows modifications to be carried out in vivo. The ability to site-specifically direct lab-synthesized chemical moieties into proteins allows many types of studies that would otherwise be extremely difficult, such as:
- Probing protein structure and function: By using amino acids with slightly different size such as O-methyltyrosine or dansylalanine instead of tyrosine, and by inserting genetically coded reporter moieties (color-changing and/or spin-active) into selected protein sites, chemical information about the protein's structure and function can be measured.
- Probing the role of post-translational modifications in protein structure and function: By using amino acids that mimic post-translational modifications such as phosphoserine, biologically active protein can be obtained, and the site-specific nature of the amino acid incorporation can lead to information on how the position, density, and distribution of protein phosphorylation effect protein function.[45][46][47][48]
- Identifying and regulating protein activity: By using photocaged aminoacids, protein function can be "switched" on or off by illuminating the organism.
- Changing the mode of action of a protein: One can start with the gene for a protein that binds a certain sequence of DNA and, by inserting a chemically active amino acid into the binding site, convert it to a protein that cuts the DNA rather than binding it.
- Improving immunogenicity and overcoming self-tolerance: By replacing strategically chosen tyrosines with p-nitro phenylalanine, a tolerated self-protein can be made immunogenic.[49]
- Selective destruction of selected cellular components: using an expanded genetic code, unnatural, destructive chemical moieties (sometimes called "chemical warheads") can be incorporated into proteins that target specific cellular components.[50]
- Producing better protein: the evolution of T7 bacteriophages on a non-evolving E. coli strain that encoded 3-iodotyrosine on the amber codon, resulted in a population fitter than wild-type thanks to the presence of iodotyrosine in its proteome[51]
Future
The expansion of the genetic code is still in its infancy. Current methodology uses only one non-standard amino acid at the time, whereas ideally multiple could be used.
Recoded synthetic genome
One way to achieve the encoding of multiple unnatural amino acids is by rewriting genome synthetically.[52] In 2010, at the cost of $40 million an organism, Mycoplasma laboratorium, was constructed that was controlled by a synthetic genome.[53] Due to the larger genome size this is not possible with E. coli, however several methods are being developed to overcome this, such as the fragmentation of the genome into separate linear chromosomes.[54] In addition to the elimination of the usage of rare codons, the specificity of the system needs to be increased as many tRNA recognise several codons[52]
Expanded genetic alphabet
Another approach is to expand the number of nucleobases to increase the coding capacity.
An unnatural base pair (UBP) is a designed subunit (or nucleobase) of DNA which is created in a laboratory and does not occur in nature. A demonstration of UBPs were achieved in vitro by Ichiro Hirao's group at RIKEN institute in Japan. In 2002, they developed an unnatural base pair between 2-amino-8-(2-thienyl)purine (s) and pyridine-2-one (y) that functions in vitro in transcription and translation for the site-specific incorporation of non-standard amino acids into proteins.[55] In 2006, they created 7-(2-thienyl)imidazo[4,5-b]pyridine (Ds) and pyrrole-2-carbaldehyde (Pa) as a third base pair for replication and transcription.[56] Afterward, Ds and 4-[3-(6-aminohexanamido)-1-propynyl]-2-nitropyrrole (Px) was discovered as a high fidelity pair in PCR amplification.[57][58] In 2013, they applied the Ds-Px pair to DNA aptamer generation by in vitro selection (SELEX) and demonstrated the genetic alphabet expansion significantly augment DNA aptamer affinities to target proteins.[59]
In 2012, a group of American scientists led by Floyd Romesberg, a chemical biologist at the Scripps Research Institute in San Diego, California, published that his team designed an unnatural base pair (UBP).[60] The two new artificial nucleotides or Unnatural Base Pair (UBP) were named d5SICS and dNaM. More technically, these artificial nucleotides bearing hydrophobic nucleobases, feature two fused aromatic rings that form a (d5SICS–dNaM) complex or base pair in DNA.[61][62] In 2014 the same team from the Scripps Research Institute reported that they synthesized a stretch of circular DNA known as a plasmid containing natural T-A and C-G base pairs along with the best-performing UBP Romesberg's laboratory had designed, and inserted it into cells of the common bacterium E. coli that successfully replicated the unnatural base pairs through multiple generations.[63] This is the first known example of a living organism passing along an expanded genetic code to subsequent generations.[61][64] This was in part achieved by the addition of a supportive algal gene that expresses a nucleotide triphosphate transporter which efficiently imports the triphosphates of both d5SICSTP and dNaMTP into E. coli bacteria.[61] Then, the natural bacterial replication pathways use them to accurately replicate the plasmid containing d5SICS–dNaM.
The successful incorporation of a third base pair into a living micro-organism is a significant breakthrough toward the goal of greatly expanding the number of amino acids which can be encoded by DNA, thereby expanding the potential for living organisms to produce novel proteins.[63] The artificial strings of DNA do not encode for anything yet, but scientists speculate they could be designed to manufacture new proteins which could have industrial or pharmaceutical uses.[65]
In May 2014, researchers announced that they had successfully introduced two new artificial nucleotides into bacterial DNA, and by including individual artificial nucleotides in the culture media, were able to passage the bacteria 24 times; they did not create mRNA or proteins able to use the artificial nucleotides.[61][66][67][68]
Related methods
Alloprotein
There have been many studies that have produced protein with non-standard amino acids, but they do not alter the genetic code. These protein, called alloprotein, are made by incubating cells with an unnatural amino acid in the absence of a similar coded amino acid in order for the former to be incorporated into protein in place of the latter, for example L-2-aminohexanoic acid (Ahx) for methionine (Met).[69]
These studies rely on the natural promiscuous activity of the amino-acyl synthase to add to its target tRNA an unnatural amino acid similar to the natural substrate, for example methionyl-tRNA synthase's mistaking isoleucine for methionine.[70] In protein crystallography, for example, the addition of selenomethionine to the media of a culture of a methionine-auxotrophic strain results in proteins containing selenomethionine as opposed to methionine (viz. Multi-wavelength anomalous dispersion for reason).[71] Another example is that photoleucine and photomethionine are added instead of leucine and methionine to cross-label protein.[72] Similarly, some tellurium-tolerant fungi can incorporate tellurocysteine and telluromethionine into their protein instead of cysteine and methionine.[73] The objective of expanding the genetic code is more radical as it does not replace an amino acid, but it adds one or more to the code.
in vitro synthesis
The genetic code expansion described above is in vivo. An alternative is the change of coding in vitro translation experiments. This requires the depletion of all tRNAs and the selective reintroduction of certain aminoacylated-tRNAs, some chemically aminoacylated.[74]
Chemical synthesis
There are several techniques to produce peptides chemically, generally it is by solid-phase protection chemistry. This means that any (protected) amino acid can be added into the nascent sequence.
See also
- List of genetic codes
- Bioengineering
- Directed evolution
- Nucleic acid analogue
- Protein labelling
- Protein methods
- Synthetic biology
- Xenobiology
References
- ↑ Xie, J; Schultz, PG (2005). "Adding amino acids to the genetic repertoire". Current Opinion in Chemical Biology. 9 (6): 548–54. doi:10.1016/j.cbpa.2005.10.011. PMID 16260173.
- 1 2 3 4 5 Wang, L.; Brock, A.; Herberich, B.; Schultz, P. G. (April 2001). "Expanding the Genetic Code of Escherichia coli". Science. 292 (5516): 498–500. Bibcode:2001Sci...292..498W. doi:10.1126/science.1060077. PMID 11313494.
- 1 2 Alberts, et. al, Bruce (2008). Molecular Biology of the Cell (5th ed.). New York: Garland Science. ISBN 0-8153-4105-9.
- ↑ Woese, et. al, Carl (2000). "Aminoacyl-tRNA synthetases, the genetic code, and the evolutionary process.". Microbiol. Mol. Biol. Rev. 64: 202–236. doi:10.1128/mmbr.64.1.202-236.2000.
- ↑ Sakamoto, K. (2002). "Site-specific incorporation of an unnatural amino acid into proteins in mammalian cells". Nucleic Acids Research. 30 (21): 4692–4699. doi:10.1093/nar/gkf589. PMC 135798
 . PMID 12409460.
. PMID 12409460. - 1 2 3 Liu, C. C.; Schultz, P. G. (2010). "Adding new chemistries to the genetic code". Annual Review of Biochemistry. 79: 413–44. doi:10.1146/annurev.biochem.052308.105824. PMID 20307192.
- ↑ Summerer, D; Chen, S; Wu, N; Deiters, A; Chin, J. W.; Schultz, P. G. (2006). "A genetically encoded fluorescent amino acid". Proceedings of the National Academy of Sciences. 103 (26): 9785–9. Bibcode:2006PNAS..103.9785S. doi:10.1073/pnas.0603965103. PMC 1502531. PMID 16785423.
- 1 2 Steinfeld, J. B.; Aerni, H. R.; Rogulina, S; Liu, Y; Rinehart, J (2014). "Expanded cellular amino acid pools containing phosphoserine, phosphothreonine, and phosphotyrosine". ACS Chemical Biology. 9 (5): 1104–12. doi:10.1021/cb5000532. PMC 4027946. PMID 24646179.
- ↑ Wang, L; Xie, J; Schultz, P. G. (2006). "Expanding the genetic code". Annual Review of Biophysics and Biomolecular Structure. 35: 225–49. doi:10.1146/annurev.biophys.35.101105.121507. PMID 16689635.
- ↑ Young, T. S.; Schultz, P. G. (2010). "Beyond the canonical 20 amino acids: Expanding the genetic lexicon". Journal of Biological Chemistry. 285 (15): 11039–44. doi:10.1074/jbc.R109.091306. PMC 2856976. PMID 20147747.
- ↑ Wang, L; Xie, J; Schultz, P. G. (2006). "Expanding the genetic code". Annual Review of Biophysics and Biomolecular Structure. 35: 225–49. doi:10.1146/annurev.biophys.35.101105.121507. PMID 16689635.
- 1 2 "The Peter G. Schultz Laboratory". Schultz.scripps.edu. Retrieved 2015-05-05.
- ↑ Cardillo, G; Gentilucci, L; Tolomelli, A (March 2006). "Unusual amino acids: synthesis and introduction into naturally occurring peptides and biologically active analogues.". Mini reviews in medicinal chemistry. 6 (3): 293–304. doi:10.2174/138955706776073394. PMID 16515468.
- ↑ Journal of the American Chemical Society. 2003 Jan 29;125(4):935-9. Generation of a bacterium with a 21 amino acid genetic code. Mehl RA, Anderson JC, Santoro SW, Wang L, Martin AB, King DS, Horn DM, Schultz PG.
- ↑ "context :: 21-amino-acid bacteria: expanding the genetic code". Straddle3.net. Retrieved 2015-05-05.
- ↑ Koonin, E. V.; Novozhilov, A. S. (2009). "Origin and evolution of the genetic code: The universal enigma". IUBMB Life. 61 (2): 99–111. doi:10.1002/iub.146. PMC 3293468. PMID 19117371.
- ↑ Taylor, Stanley R. Maloy, Valley J. Stewart, Ronald K. (1996). Genetic analysis of pathogenic bacteria : a laboratory manual. New York: Cold Spring Harbor Laboratory. ISBN 978-0-87969-453-1.
- ↑ Normanly, J; Kleina, L.G.; Masson, J.M.; Abelson, J.; Miller, J.H. (1990). "Construction of Escherichia coli amber suppressor tRNA genes. III. Determination of tRNA specificity". J. Mol. Biol. 213 (4): 719–726. doi:10.1016/S0022-2836(05)80258-X. PMID 2141650.
- ↑ Wang, L.; Magliery, T.J.; Liu, D.R.; Schultz, P.G. (2000). "A new functional suppressor tRNA/aminoacyl-tRNA synthetase pair for the in vivo incorporation of unnatural amino acids into proteins" (PDF). J. Am. Chem. Soc. 122 (20): 5010–5011. doi:10.1021/ja000595y.
- ↑ Wang, L; Brock, A; Herberich, B; Schultz, PG (20 April 2001). "Expanding the genetic code of Escherichia coli.". Science. 292 (5516): 498–500. Bibcode:2001Sci...292..498W. doi:10.1126/science.1060077. PMID 11313494.
- ↑ Wang, L; Brock, A; Schultz, PG (6 March 2002). "Adding L-3-(2-Naphthyl)alanine to the genetic code of E. coli.". Journal of the American Chemical Society. 124 (9): 1836–7. doi:10.1021/ja012307j. PMID 11866580.
- ↑ Chin, JW; Martin, AB; King, DS; Wang, L; Schultz, PG (20 August 2002). "Addition of a photocrosslinking amino acid to the genetic code of Escherichiacoli.". Proceedings of the National Academy of Sciences of the United States of America. 99 (17): 11020–4. Bibcode:2002PNAS...9911020C. doi:10.1073/pnas.172226299. PMID 12154230.
- ↑ Aerni, H. R.; Shifman, M. A.; Rogulina, S; O'Donoghue, P; Rinehart, J (2015). "Revealing the amino acid composition of proteins within an expanded genetic code". Nucleic Acids Research. 43 (2): e8. doi:10.1093/nar/gku1087. PMID 25378305.
- ↑ Isaacs, F. J.; Carr, P. A.; Wang, H. H.; Lajoie, M. J.; Sterling, B; Kraal, L; Tolonen, A. C.; Gianoulis, T. A.; Goodman, D. B.; Reppas, N. B.; Emig, C. J.; Bang, D; Hwang, S. J.; Jewett, M. C.; Jacobson, J. M.; Church, G. M. (2011). "Precise manipulation of chromosomes in vivo enables genome-wide codon replacement". Science. 333 (6040): 348–53. Bibcode:2011Sci...333..348I. doi:10.1126/science.1205822. PMID 21764749.
- ↑ Lajoie, M. J.; Rovner, A. J.; Goodman, D. B.; Aerni, H. R.; Haimovich, A. D.; Kuznetsov, G; Mercer, J. A.; Wang, H. H.; Carr, P. A.; Mosberg, J. A.; Rohland, N; Schultz, P. G.; Jacobson, J. M.; Rinehart, J; Church, G. M.; Isaacs, F. J. (2013). "Genomically recoded organisms expand biological functions". Science. 342 (6156): 357–60. Bibcode:2013Sci...342..357L. doi:10.1126/science.1241459. PMID 24136966.
- ↑ Mandell, D. J.; Lajoie, M. J.; Mee, M. T.; Takeuchi, R; Kuznetsov, G; Norville, J. E.; Gregg, C. J.; Stoddard, B. L.; Church, G. M. (2015). "Biocontainment of genetically modified organisms by synthetic protein design". Nature. 518 (7537): 55–60. Bibcode:2015Natur.518...55M. doi:10.1038/nature14121. PMID 25607366.
- ↑ Zeng, Y; Wang, W; Liu, W. R. (2014). "Towards reassigning the rare AGG codon in Escherichia coli". ChemBioChem. 15 (12): 1750–4. doi:10.1002/cbic.201400075. PMC 4167342. PMID 25044341.
- ↑ Bohlke, N; Budisa, N (February 2014). "Sense codon emancipation for proteome-wide incorporation of noncanonical amino acids: rare isoleucine codon AUA as a target for genetic code expansion.". FEMS microbiology letters. 351 (2): 133–44. doi:10.1111/1574-6968.12371. PMID 24433543.
- ↑ Hoesl, M. G.; Budisa, N. (2012). "Recent advances in genetic code engineering in Escherichia coli". Current Opinion in Biotechnology. 23 (5): 751–7. doi:10.1016/j.copbio.2011.12.027. PMID 22237016.
- ↑ Neumann, H; Wang, K; Davis, L; Garcia-Alai, M; Chin, JW (18 March 2010). "Encoding multiple unnatural amino acids via evolution of a quadruplet-decoding ribosome.". Nature. 464 (7287): 441–4. Bibcode:2010Natur.464..441N. doi:10.1038/nature08817. PMID 20154731.
- ↑ Watanabe, T; Muranaka, N; Hohsaka, T. (2008). "Four-base codon-mediated saturation mutagenesis in a cell-free translation system". J Biosci Bioeng. 105 (3): 211–5. doi:10.1263/jbb.105.211. PMID 18397770.
- ↑ Anderson, J.C.; Wu, N.; Santoro, S.W.; Lakshman, V.; King, D.S.; Schultz, P.G. (2004). "An expanded genetic code with a functional quadruplet codon". Proc Natl Acad Sci USA. 101 (20): 7566–7571. Bibcode:2004PNAS..101.7566A. doi:10.1073/pnas.0401517101. PMC 419646. PMID 15138302.
- ↑ Santoro, S.W.; Anderson, J.C.; Lakshman, V.; Schultz, P.G. (2003). "An archaebacteria-derived glutamyl-tRNA synthetase and tRNA pair for unnatural amino acid mutagenesis of proteins in Escherichia coli". Nucleic Acids Res. 31 (23): 6700–6709. doi:10.1093/nar/gkg903. PMC 290271. PMID 14627803.
- ↑ Anderson, J.C.; Schultz, P.G. (2003). "Adaptation of an orthogonal archaeal leucyl-tRNA and synthetase pair for four-base, amber, and opal suppression". Biochemistry. 42 (32): 9598–9608. doi:10.1021/bi034550w. PMID 12911301.
- ↑ Minaba, Masaomi; Kato, Yusuke (2013). "High-Yield, Zero-Leakage Expression System with a Translational Switch Using Site-Specific Unnatural Amino Acid Incorporation". Applied and Environmental Microbiology. 80 (5). doi:10.1128/AEM.03417-13.
- ↑ Chin, J.W.; Cropp, T.A.; Anderson, J.C.; Mukherji, M.; Zhang, Z.; Schultz, P.G. (2003). "An expanded eukaryotic genetic code". Science. 301 (5635): 964–967. Bibcode:2003Sci...301..964C. doi:10.1126/science.1084772. PMID 12920298.
- ↑ Wu, N.; Deiters, A.; Cropp, T.A.; King, D.; Schultz, P.G. (2004). "A genetically encoded photocaged amino Acid". J Am Chem Soc. 126 (44): 14306–14307. doi:10.1021/ja040175z. PMID 15521721.
- ↑ Kowal, A.K.; Kohrer, C.; RajBhandary, U.L. (2001). "Twenty-first aminoacyl-tRNA synthetase–suppressor tRNA pairs for possible use in site-specific incorporation of amino acid analogues into proteins in eukaryotes and in eubacteria". Proc Natl Acad Sci USA. 98 (5): 2268–2273. Bibcode:2001PNAS...98.2268K. doi:10.1073/pnas.031488298. PMC 30127. PMID 11226228.
- ↑ Hancock, S. M.; Uprety, R; Deiters, A; Chin, J. W. (2010). "Expanding the genetic code of yeast for incorporation of diverse unnatural amino acids via a pyrrolysyl-tRNA synthetase/tRNA pair". Journal of the American Chemical Society. 132 (42): 14819–24. doi:10.1021/ja104609m. PMC 2956376. PMID 20925334.
- ↑ Kang, Ji-Yong (2013). "In vivo Expression of a Light-activatable Potassium Channel Using Unnatural Amino Acids". Neuron. doi:10.1016/j.neuron.2013.08.016.
- ↑ Sakamoto, K.; Hayashi, A.; Sakamoto, A.; Kiga, D.; Nakayama, H.; Soma, A.; Kobayashi, T.; Kitabatake, M.; et al. (2002). "Site-specific incorporation of an unnatural amino acid into proteins in mammalian cells". Nucleic Acids Res. 30 (21): 4692–4699. doi:10.1093/nar/gkf589. PMC 135798. PMID 12409460.
- ↑ Zhang, Z.; Alfonta, L.; Tian, F.; Bursulaya, B.; Uryu, S.; King, D.S.; Schultz, P.G. (2004). "Selective incorporation of 5-hydroxytryptophan into proteins in mammalian cells". Proc. Natl. Acad. Sci. USA. 101 (24): 8882–8887. Bibcode:2004PNAS..101.8882Z. doi:10.1073/pnas.0307029101. PMC 428441. PMID 15187228.
- ↑ Wang, W.; Takimoto, J.; Louie, G.V.; Baiga, T.J.; Noel, J.P.; Lee, K.F.; Slesinger, P.A.; Wang, L. (2007). "Genetically encoding unnatural amino acids for cellular and neuronal studies". Nat. Neurosci. 10 (8): 1063–1072. doi:10.1038/nn1932. PMC 2692200. PMID 17603477.
- ↑ Wang, Q; Parrish, AR; Wang, L (2009). "Expanding the Genetic Code for Biological Studies". Chemistry & Biology. 16 (3): 323–36. doi:10.1016/j.chembiol.2009.03.001. PMC 2696486. PMID 19318213.
- ↑ Park, Hee-Sung; Hohn, Michael J.; Umehara, Takuya; Guo, Li-Tao; Osborne, Edith M.; Benner, Jack; Noren, Christopher J.; Rinehart, Jesse; Söll, Dieter (2011-08-26). "Expanding the Genetic Code of Escherichia coli with Phosphoserine". Science. 333 (6046): 1151–1154. Bibcode:2011Sci...333.1151P. doi:10.1126/science.1207203. ISSN 0036-8075. PMID 21868676.
- ↑ Oza, Javin P.; Aerni, Hans R.; Pirman, Natasha L.; Barber, Karl W.; ter Haar, Charlotte M.; Rogulina, Svetlana; Amrofell, Matthew B.; Isaacs, Farren J.; Rinehart, Jesse (2015-09-09). "Robust production of recombinant phosphoproteins using cell-free protein synthesis". Nature Communications. 6: 8168. doi:10.1038/ncomms9168. PMC 4566161. PMID 26350765.
- ↑ Pirman, Natasha L.; Barber, Karl W.; Aerni, Hans R.; Ma, Natalie J.; Haimovich, Adrian D.; Rogulina, Svetlana; Isaacs, Farren J.; Rinehart, Jesse (2015-09-09). "A flexible codon in genomically recoded Escherichia coli permits programmable protein phosphorylation". Nature Communications. 6: 8130. doi:10.1038/ncomms9130. PMC 4566969. PMID 26350500.
- ↑ Rogerson, Daniel T; Sachdeva, Amit; Wang, Kaihang; Haq, Tamanna; Kazlauskaite, Agne; Hancock, Susan M; Huguenin-Dezot, Nicolas; Muqit, Miratul M K; Fry, Andrew M (2015-01-01). "Efficient genetic encoding of phosphoserine and its nonhydrolyzable analog". Nature Chemical Biology. 11 (7): 496–503. doi:10.1038/nchembio.1823. PMID 26030730.
- ↑ Gauba, V; Grünewald, J; Gorney, V; Deaton, L. M.; Kang, M; Bursulaya, B; Ou, W; Lerner, R. A.; Schmedt, C; Geierstanger, B. H.; Schultz, P. G.; Ramirez-Montagut, T (2011). "Loss of CD4 T-cell-dependent tolerance to proteins with modified amino acids". Proceedings of the National Academy of Sciences. 108 (31): 12821–6. Bibcode:2011PNAS..10812821G. doi:10.1073/pnas.1110042108. PMC 3150954. PMID 21768354.
- ↑ Liu, CC; Mack, AV; Brustad, EM; Mills, JH; Groff, D; Smider, VV; Schultz, PG. (2009). "The Evolution of Proteins with Genetically Encoded "Chemical Warheads"". J Am Chem Soc. 131 (28): 9616–7. doi:10.1021/ja902985e. PMC 2745334. PMID 19555063.
- ↑ Hammerling, M. J.; Ellefson, J. W.; Boutz, D. R.; Marcotte, E. M.; Ellington, A. D.; Barrick, J. E. (2014). "Bacteriophages use an expanded genetic code on evolutionary paths to higher fitness". Nature Chemical Biology. 10 (3): 178–80. doi:10.1038/nchembio.1450. PMC 3932624. PMID 24487692.
- 1 2 Krishnakumar, R; Ling, J (31 January 2014). "Experimental challenges of sense codon reassignment: an innovative approach to genetic code expansion.". FEBS Letters. 588 (3): 383–8. doi:10.1016/j.febslet.2013.11.039. PMID 24333334.
- ↑ Gibson, DG; Glass, JI; Lartigue, C; Noskov, VN; Chuang, RY; Algire, MA; Benders, GA; Montague, MG; Ma, L; Moodie, MM; Merryman, C; Vashee, S; Krishnakumar, R; Assad-Garcia, N; Andrews-Pfannkoch, C; Denisova, EA; Young, L; Qi, ZQ; Segall-Shapiro, TH; Calvey, CH; Parmar, PP; Hutchison CA, 3rd; Smith, HO; Venter, JC (2 July 2010). "Creation of a bacterial cell controlled by a chemically synthesized genome.". Science. 329 (5987): 52–6. Bibcode:2010Sci...329...52G. doi:10.1126/science.1190719. PMID 20488990.
- ↑ Liang, X; Baek, CH; Katzen, F (20 December 2013). "Escherichia coli with two linear chromosomes.". ACS Synthetic Biology. 2 (12): 734–40. doi:10.1021/sb400079u. PMID 24160891.
- ↑ Hirao, I.; et al. (2002). "An unnatural base pair for incorporating amino acid analogs into proteins". Nat. Biotechnol. 20: 177–182. doi:10.1038/nbt0202-177.
- ↑ Hirao, I.; et al. (2006). "An unnatural hydrophobic base pair system: site-specific incorporation of nucleotide analogs into DNA and RNA". Nat. Methods. 6: 729–735. doi:10.1038/nmeth915.
- ↑ Kimoto, M. et al. (2009) An unnatural base pair system for efficient PCR amplification and functionalization of DNA molecules. Nucleic acids Res. 37, e14
- ↑ Yamashige, R.; et al. "Highly specific unnatural base pair systems as a third base pair for PCR amplification". Nucleic Acids Res. 40: 2793–2806. doi:10.1093/nar/gkr1068.
- ↑ Kimoto, M.; et al. (2013). "Generation of high-affinity DNA aptamers using an expanded genetic alphabet". Nat. Biotechnol. 31: 453–457. doi:10.1038/nbt.2556.
- ↑ Malyshev, Denis A.; Dhami, Kirandeep; Quach, Henry T.; Lavergne, Thomas; Ordoukhanian, Phillip (24 July 2012). "Efficient and sequence-independent replication of DNA containing a third base pair establishes a functional six-letter genetic alphabet". Proceedings of the National Academy of Sciences of the United States of America. 109 (30): 12005–12010. Bibcode:2012PNAS..10912005M. doi:10.1073/pnas.1205176109. Retrieved 2014-05-11.
- 1 2 3 4 Malyshev, Denis A.; Dhami, Kirandeep; Lavergne, Thomas; Chen, Tingjian; Dai, Nan; Foster, Jeremy M.; Corrêa, Ivan R.; Romesberg, Floyd E. (May 7, 2014). "A semi-synthetic organism with an expanded genetic alphabet". Nature. 509: 385–388. Bibcode:2014Natur.509..385M. doi:10.1038/nature13314. PMC 4058825. PMID 24805238. Retrieved May 7, 2014.
- ↑ Callaway, Ewan (May 7, 2014). "Scientists Create First Living Organism With 'Artificial' DNA". Nature News. Huffington Post. Retrieved 8 May 2014.
- 1 2 Fikes, Bradley J. (May 8, 2014). "Life engineered with expanded genetic code". San Diego Union Tribune. Retrieved 8 May 2014.
- ↑ Sample, Ian (May 7, 2014). "First life forms to pass on artificial DNA engineered by US scientists". The Guardian. Retrieved 8 May 2014.
- ↑ Pollack, Andrew (May 7, 2014). "Scientists Add Letters to DNA's Alphabet, Raising Hope and Fear". New York Times. Retrieved 8 May 2014.
- ↑ Pollack, Andrew (May 7, 2014). "Researchers Report Breakthrough in Creating Artificial Genetic Code". New York Times. Retrieved May 7, 2014.
- ↑ Callaway, Ewen (May 7, 2014). "First life with 'alien' DNA". Nature. doi:10.1038/nature.2014.15179. Retrieved May 7, 2014.
- ↑ Amos, Jonathan (8 May 2014). "Semi-synthetic bug extends 'life's alphabet'". BBC News. Retrieved 2014-05-09.
- ↑ Koide, H.; Yokoyama, S.; Kawai, G.; Ha, J. M.; Oka, T.; Kawai, S.; Miyake, T.; Fuwa, T.; Miyazawa, T. (1988). "Biosynthesis of a protein containing a nonprotein amino acid by Escherichia coli: L-2-aminohexanoic acid at position 21 in human epidermal growth factor". Proceedings of the National Academy of Sciences of the United States of America. 85 (17): 6237–6241. Bibcode:1988PNAS...85.6237K. doi:10.1073/pnas.85.17.6237. PMC 281944. PMID 3045813.
- ↑ Ferla, M. P.; Patrick, W. M. (2014). "Bacterial methionine biosynthesis". Microbiology. 160 (Pt 8): 1571–84. doi:10.1099/mic.0.077826-0. PMID 24939187.
- ↑ Doublié, S. (2007). "Production of Selenomethionyl Proteins in Prokaryotic and Eukaryotic Expression Systems". Macromolecular Crystallography Protocols. Methods in Molecular Biology. 363. p. 91. doi:10.1007/978-1-59745-209-0_5. ISBN 978-1-58829-292-6.
- ↑ Suchanek, Monika; Radzikowska, Anna; Thiele, Christoph (2005). "Photo-leucine and photo-methionine allow identification of protein-protein interactions in living cells". Nature Methods. 2 (4): 261–268. doi:10.1038/NMETH752.
- ↑ Ramadan, S. E.; Razak, A. A.; Ragab, A. M.; El-Meleigy, M. (1989). "Incorporation of tellurium into amino acids and proteins in a tellurium-tolerant fungi". Biological trace element research. 20 (3): 225–232. doi:10.1007/BF02917437. PMID 2484755.
- ↑ Hong, SH; Kwon, YC; Jewett, MC (2014). "Non-standard amino acid incorporation into proteins using Escherichia coli cell-free protein synthesis". Frontiers in Chemistry. 2: 34. Bibcode:2014FrCh....2...34H. doi:10.3389/fchem.2014.00034. PMC 4050362. PMID 24959531.
| Key components | |
|---|---|
| Fields | |
| Archaeogenetics of | |
| Related topics | |