Molecular evolution
| Part of a series on |
| Evolutionary biology |
|---|
 |
|
History of evolutionary theory |
|
Fields and applications
|
|
Molecular evolution is the process of change in the sequence composition of cellular molecules such as DNA, RNA, and proteins across generations. The field of molecular evolution uses principles of evolutionary biology and population genetics to explain patterns in these changes. Major topics in molecular evolution concern the rates and impacts of single nucleotide changes, neutral evolution vs. natural selection, origins of new genes, the genetic nature of complex traits, the genetic basis of speciation, evolution of development, and ways that evolutionary forces influence genomic and phenotypic changes.
Forces in molecular evolution
The content and structure of a genome is the product of the molecular and population genetic forces which act upon that genome. Novel genetic variants will arise through mutation and will spread and be maintained in populations due to genetic drift or natural selection.
Mutation

Mutations are permanent, transmissible changes to the genetic material (DNA or RNA) of a cell or virus. Mutations result from errors in DNA replication during cell division and by exposure to radiation, chemicals, and other environmental stressors, or viruses and transposable elements. Most mutations that occur are single nucleotide polymorphisms which modify single bases of the DNA sequence, resulting in point mutations. Other types of mutations modify larger segments of DNA and can cause duplications, insertions, deletions, inversions, and translocations.
Most organisms display a strong bias in the types of mutations that occur with strong influence in GC-content. Transitions (A ↔ G or C ↔ T) are more common than transversions (purine (adenine or guanine)) ↔ pyrimidine (cytosine or thymine, or in RNA, uracil))[1] and are less likely to alter amino acid sequences of proteins.
Mutations are stochastic and typically occur randomly across genes. Mutation rates for single nucleotide sites for most organisms are very low, roughly 10−9 to 10−8 per site per generation, though some viruses have higher mutation rates on the order of 10−6 per site per generation. Among these mutations, some will be neutral or beneficial and will remain in the genome unless lost via genetic drift, and others will be detrimental and will be eliminated from the genome by natural selection.
Because mutations are extremely rare, they accumulate very slowly across generations. While the number of mutations which appears in any single generation may vary, over very long time periods they will appear to accumulate at a regular pace. Using the mutation rate per generation and the number of nucleotide differences between two sequences, divergence times can be estimated effectively via the molecular clock.
Recombination
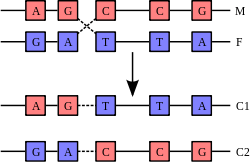
Recombination is a process that results in genetic exchange between chromosomes or chromosomal regions. Recombination counteracts physical linkage between adjacent genes, thereby reducing genetic hitchhiking. The resulting independent inheritance of genes results in more efficient selection, meaning that regions with higher recombination will harbor fewer detrimental mutations, more selectively favored variants, and fewer errors in replication and repair. Recombination can also generate particular types of mutations if chromosomes are misaligned.
Gene conversion
Gene conversion is a type of recombination that is the product of DNA repair where nucleotide damage is corrected using an homologous genomic region as a template. Damaged bases are first excised, the damaged strand is then aligned with an undamaged homolog, and DNA synthesis repairs the excised region using the undamaged strand as a guide. Gene conversion is often responsible for homogenizing sequences of duplicate genes over long time periods, reducing nucleotide divergence.
Genetic drift
Genetic drift is the change of allele frequencies from one generation to the next due to stochastic effects of random sampling in finite populations. Some existing variants have no effect on fitness and may increase or decrease in frequency simply due to chance. "Nearly neutral" variants whose selection coefficient is close to a threshold value of 1 / the effective population size will also be affected by chance as well as by selection and mutation. Many genomic features have been ascribed to accumulation of nearly neutral detrimental mutations as a result of small effective population sizes.[2] With a smaller effective population size, a larger variety of mutations will behave as if they are neutral due to inefficiency of selection.
Selection
Selection occurs when organisms with greater fitness, i.e. greater ability to survive or reproduce, are favored in subsequent generations, thereby increasing the instance of underlying genetic variants in a population. Selection can be the product of natural selection, artificial selection, or sexual selection. Natural selection is any selective process that occurs due to the fitness of an organism to its environment. In contrast sexual selection is a product of mate choice and can favor the spread of genetic variants which act counter to natural selection but increase desirability to the opposite sex or increase mating success. Artificial selection, also known as selective breeding, is imposed by an outside entity, typically humans, in order to increase the frequency of desired traits.
The principles of population genetics apply similarly to all types of selection, though in fact each may produce distinct effects due to clustering of genes with different functions in different parts of the genome, or due to different properties of genes in particular functional classes. For instance, sexual selection could be more likely to affect molecular evolution of the sex chromosomes due to clustering of sex specific genes on the X,Y,Z or W.
Selection can operate at the gene level at the expense of organismal fitness, resulting in a selective advantage for selfish genetic elements in spite of a host cost. Examples of such selfish elements include transposable elements, meiotic drivers, killer X chromosomes, selfish mitochondria, and self-propagating introns. (See Intragenomic conflict.)
Genome architecture
Genome size
Genome size is influenced by the amount of repetitive DNA as well as number of genes in an organism. The C-value paradox refers to the lack of correlation between organism 'complexity' and genome size. Explanations for the so-called paradox are two-fold. First, repetitive genetic elements can comprise large portions of the genome for many organisms, thereby inflating DNA content of the haploid genome. Secondly, the number of genes is not necessarily indicative of the number of developmental stages or tissue types in an organism. An organism with few developmental stages or tissue types may have large numbers of genes that influence non-developmental phenotypes, inflating gene content relative to developmental gene families.
Neutral explanations for genome size suggest that when population sizes are small, many mutations become nearly neutral. Hence, in small populations repetitive content and other 'junk' DNA can accumulate without placing the organism at a competitive disadvantage. There is little evidence to suggest that genome size is under strong widespread selection in multicellular eukaryotes. Genome size, independent of gene content, correlates poorly with most physiological traits and many eukaryotes, including mammals, harbor very large amounts of repetitive DNA.
However, birds likely have experienced strong selection for reduced genome size, in response to changing energetic needs for flight. Birds, unlike humans, produce nucleated red blood cells, and larger nuclei lead to lower levels of oxygen transport. Bird metabolism is far higher than that of mammals, due largely to flight, and oxygen needs are high. Hence, most birds have small, compact genomes with few repetitive elements. Indirect evidence suggests that non-avian theropod dinosaur ancestors of modern birds [3] also had reduced genome sizes, consistent with endothermy and high energetic needs for running speed. Many bacteria have also experienced selection for small genome size, as time of replication and energy consumption are so tightly correlated with fitness.
Repetitive elements
Transposable elements are self-replicating, selfish genetic elements which are capable of proliferating within host genomes. Many transposable elements are related to viruses, and share several proteins in common.
DNA transposons are cut and paste transposable elements which excise DNA and move it to alternate sections of the genome.
non-LTR retrotransposons
LTR retrotransposons
Helitrons
Alu elements comprise over 10% of the human genome. They are short non-autonomous repeat sequences.
Chromosome number and organization
The number of chromosomes in an organism's genome also does not necessarily correlate with the amount of DNA in its genome. The ant Myrmecia pilosula has only a single pair of chromosomes[4] whereas the Adders-tongue fern Ophioglossum reticulatum has up to 1260 chromosomes.[5] Cilliate genomes house each gene in individual chromosomes, resulting in a genome which is not physically linked. Reduced linkage through creation of additional chromosomes should effectively increase the efficiency of selection.
Changes in chromosome number can play a key role in speciation, as differing chromosome numbers can serve as a barrier to reproduction in hybrids. Human chromosome 2 was created from a fusion of two chimpanzee chromosomes and still contains central telomeres as well as a vestigial second centromere. Polyploidy, especially allopolyploidy, which occurs often in plants, can also result in reproductive incompatibilities with parental species. Agrodiatus blue butterflies have diverse chromosome numbers ranging from n=10 to n=134 and additionally have one of the highest rates of speciation identified to date.[6]
Gene content and distribution
Different organisms house different numbers of genes within their genomes as well as different patterns in the distribution of genes throughout the genome. Some organisms, such as most bacteria, Drosophila, and Arabidopsis have particularly compact genomes with little repetitive content or non-coding DNA. Other organisms, like mammals or maize, have large amounts of repetitive DNA, long introns, and substantial spacing between different genes. The content and distribution of genes within the genome can influence the rate at which certain types of mutations occur and can influence the subsequent evolution of different species. Genes with longer introns are more likely to recombine due to increased physical distance over the coding sequence. As such, long introns may facilitate ectopic recombination, and result in higher rates of new gene formation.
Organelles
In addition to the nuclear genome, endosymbiont organelles contain their own genetic material typically as circular plasmids. Mitochondrial and chloroplast DNA varies across taxa, but membrane-bound proteins, especially electron transport chain constituents are most often encoded in the organelle. Chloroplasts and mitochondria are maternally inherited in most species, as the organelles must pass through the egg. In a rare departure, some species of mussels are known to inherit mitochondria from father to son.
Origins of new genes
New genes arise from several different genetic mechanisms including gene duplication, de novo origination, retrotransposition, chimeric gene formation, recruitment of non-coding sequence, and gene truncation.
Gene duplication initially leads to redundancy. However, duplicated gene sequences can mutate to develop new functions or specialize so that the new gene performs a subset of the original ancestral functions. In addition to duplicating whole genes, sometimes only a domain or part of a protein is duplicated so that the resulting gene is an elongated version of the parental gene.
Retrotransposition creates new genes by copying mRNA to DNA and inserting it into the genome. Retrogenes often insert into new genomic locations, and often develop new expression patterns and functions.
Chimeric genes form when duplication, deletion, or incomplete retrotransposition combine portions of two different coding sequences to produce a novel gene sequence. Chimeras often cause regulatory changes and can shuffle protein domains to produce novel adaptive functions.
De novo origin. Novel genes can also arise from previously non-coding DNA.[7] For instance, Levine and colleagues reported the origin of five new genes in the D. melanogaster genome from noncoding DNA.[8][9] Similar de novo origin of genes has been also shown in other organisms such as yeast,[10] rice[11] and humans.[12] De novo genes may evolve from transcripts that are already expressed at low levels.[13] Mutation of a stop codon to a regular codon or a frameshift may cause an extended protein that includes a previously non-coding sequence.
Molecular phylogenetics
Molecular systematics is the product of the traditional fields of systematics and molecular genetics. It uses DNA, RNA, or protein sequences to resolve questions in systematics, i.e. about their correct scientific classification or taxonomy from the point of view of evolutionary biology.
Molecular systematics has been made possible by the availability of techniques for DNA sequencing, which allow the determination of the exact sequence of nucleotides or bases in either DNA or RNA. At present it is still a long and expensive process to sequence the entire genome of an organism, and this has been done for only a few species. However, it is quite feasible to determine the sequence of a defined area of a particular chromosome. Typical molecular systematic analyses require the sequencing of around 1000 base pairs.
The driving forces of evolution
Depending on the relative importance assigned to the various forces of evolution, three perspectives provide evolutionary explanations for molecular evolution.[14]
Selectionist hypotheses argue that selection is the driving force of molecular evolution. While acknowledging that many mutations are neutral, selectionists attribute changes in the frequencies of neutral alleles to linkage disequilibrium with other loci that are under selection, rather than to random genetic drift.[15] Biases in codon usage are usually explained with reference to the ability of even weak selection to shape molecular evolution.[16]
Neutralist hypotheses emphasize the importance of mutation, purifying selection, and random genetic drift.[17] The introduction of the neutral theory by Kimura,[18] quickly followed by King and Jukes' own findings,[19] led to a fierce debate about the relevance of neodarwinism at the molecular level. The Neutral theory of molecular evolution proposes that most mutations in DNA are at locations not important to function or fitness. These neutral changes drift towards fixation within a population. Positive changes will be very rare, and so will not greatly contribute to DNA polymorphisms.[20] Deleterious mutations will also not contribute very much to DNA diversity because they negatively affect fitness and so will not stay in the gene pool for long.[21] This theory provides a framework for the molecular clock.[20] The fate of neutral mutations are governed by genetic drift, and contribute to both nucleotide polymorphism and fixed differences between species.[22][23]
In the strictest sense, the neutral theory is not accurate.[24] Subtle changes in DNA very often have effects, but sometimes these effects are too small for natural selection to act on.[24] Even synonymous mutations are not necessarily neutral [24] because there is not a uniform amount of each codon. The nearly neutral theory expanded the neutralist perspective, suggesting that several mutations are nearly neutral, which means both random drift and natural selection is relevant to their dynamics.[24] The main difference between the neutral theory and nearly neutral theory is that the latter focuses on weak selection, not strictly neutral.[21]
Mutationists hypotheses emphasize random drift and biases in mutation patterns.[25] Sueoka was the first to propose a modern mutationist view. He proposed that the variation in GC content was not the result of positive selection, but a consequence of the GC mutational pressure.[26]
Protein Evolution

Protein evolution describes the changes over time in protein shape, function, and composition. Through quantitative analysis and experimentation, scientists have strived to understand the rate and causes of protein evolution. Using the amino acid sequences of hemoglobin and cytochrome c from multiple species, scientists were able to derive estimations of protein evolution rates. What they found was that the rates were not the same among proteins.[21] Each protein has its own rate, and that rate is constant across phylogenies (i.e., hemoglobin does not evolve at the same rate as cytochrome c, but hemoglobins from humans, mice, etc. do have comparable rates of evolution.). Not all regions within a protein mutate at the same rate; functionally important areas mutate more slowly and amino acid substitutions involving similar amino acids occurs more often than dissimilar substitutions.[21] Overall, the level of polymorphisms in proteins seems to be fairly constant. Several species (including humans, fruit flies, and mice) have similar levels of protein polymorphism.[20]
Relation to Nucleic Acid Evolution
Protein evolution is inescapably tied to changes and selection of DNA polymorphisms and mutations because protein sequences change in response to alterations in the DNA sequence. Amino acid sequences and nucleic acid sequences do not mutate at the same rate. Due to the degenerate nature of DNA, bases can change without affecting the amino acid sequence. For example, there are six codons that code for leucine. Thus, despite the difference in mutation rates, it is essential to incorporate nucleic acid evolution into the discussion of protein evolution. At the end of the 1960s, two groups of scientists—Kimura (1968) and King and Jukes (1969)-- independently proposed that a majority of the evolutionary changes observed in proteins were neutral.[20][21] Since then, the neutral theory has been expanded upon and debated.[21]
Discordance with morphological evolution
There are sometimes discordances between molecular and morphological evolution, which are reflected in molecular and morphological systematic studies, especially of bacteria, archaea and eukaryotic microbes. These discordances can be categorized as two types: (i) one morphology, multiple lineages (e.g. morphological convergence, cryptic species) and (ii) one lineage, multiple morphologies (e.g. phenotypic plasticity, multiple life-cycle stages). Neutral evolution possibly could explain the incongruences in some cases.[27]
Journals and societies
The Society for Molecular Biology and Evolution publishes the journals "Molecular Biology and Evolution" and "Genome Biology and Evolution" and holds an annual international meeting. Other journals dedicated to molecular evolution include Journal of Molecular Evolution and Molecular Phylogenetics and Evolution. Research in molecular evolution is also published in journals of genetics, molecular biology, genomics, systematics, and evolutionary biology.
See also
- Abiogenesis
- Comparative phylogenetics
- Evolution
- E. coli long-term evolution experiment
- Evolutionary physiology
- Evolution of dietary antioxidants
- Genomic organization
- Genetic drift
- Genome evolution
- Heterotachy
- History of molecular evolution
- Horizontal gene transfer
- Human evolution
- Molecular clock
- Molecular paleontology
- Neutral theory of molecular evolution
- Nucleotide diversity
- Parsimony
- Population genetics
- Selection
References
- ↑ https://www.mun.ca/biology/scarr/Transitions_vs_Transversions.html
- ↑ Lynch, M. (2007). The Origins of Genome Architecture. Sinauer. ISBN 0-87893-484-7.
- ↑ Organ, C. L.; Shedlock, A. M.; Meade, A.; Pagel, M.; Edwards, S. V. (2007). "Origin of avian genome size and structure in nonavian dinosaurs". Nature. 446: 180–184. doi:10.1038/nature05621.
- ↑ Crosland, M.W.J., Crozier, R.H. (1986). "Myrmecia pilosula, an ant with only one pair of chromosomes". Science. 231 (4743): 1278. Bibcode:1986Sci...231.1278C. doi:10.1126/science.231.4743.1278. PMID 17839565.
- ↑ Gerardus J. H. Grubben (2004). Vegetables. PROTA. p. 404. ISBN 978-90-5782-147-9. Retrieved 10 March 2013.
- ↑ Nikolai P. Kandul; Vladimir A. Lukhtanov; Naomi E. Pierce (2007), "KARYOTYPIC DIVERSITY AND SPECIATION IN AGRODIAETUS BUTTERFLIES", Evolution, 61 (3): 546–559, doi:10.1111/j.1558-5646.2007.00046.x
- ↑ McLysaght, Aoife; Guerzoni, Daniele (31 August 2015). "New genes from non-coding sequence: the role of de novo protein-coding genes in eukaryotic evolutionary innovation". Philosophical Transactions of the Royal Society B: Biological Sciences. 370 (1678): 20140332. doi:10.1098/rstb.2014.0332.
- ↑ Levine MT, Jones CD, Kern AD, et al. (2006). "Novel genes derived from noncoding DNA in Drosophila melanogaster are frequently X-linked and exhibit testis-biased expression". Proc Natl Acad Sci USA. 103 (26): 9935–9939. Bibcode:2006PNAS..103.9935L. doi:10.1073/pnas.0509809103. PMC 1502557
 . PMID 16777968.
. PMID 16777968. - ↑ Zhou Q, Zhang G, Zhang Y, et al. (2008). "On the origin of new genes in Drosophila". Genome Res. 18 (9): 1446–1455. doi:10.1101/gr.076588.108. PMC 2527705. PMID 18550802.
- ↑ Cai J, Zhao R, Jiang H, et al. (2008). "De novo origination of a new protein-coding gene in Saccharomyces cerevisiae". Genetics. 179 (1): 487–496. doi:10.1534/genetics.107.084491. PMC 2390625. PMID 18493065.
- ↑ Xiao W, Liu H, Li Y, et al. (2009). El-Shemy HA, ed. "A rice gene of de novo origin negatively regulates pathogen- induced defense response". PLoS ONE. 4 (2): e4603. Bibcode:2009PLoSO...4.4603X. doi:10.1371/journal.pone.0004603. PMC 2643483. PMID 19240804.
- ↑ Knowles DG, McLysaght A (2009). "Recent de novo origin of human protein-coding genes". Genome Res. 19 (10): 1752–1759. doi:10.1101/gr.095026.109. PMC 2765279. PMID 19726446.
- ↑ Wilson, Ben A.; Joanna Masel (2011). "Putatively Noncoding Transcripts Show Extensive Association with Ribosomes". Genome Biology & Evolution. 3: 1245–1252. doi:10.1093/gbe/evr099.
- ↑ Graur, D. & Li, W.-H. (2000). Fundamentals of molecular evolution. Sinauer. ISBN 0-87893-266-6.
- ↑ Hahn, Matthew W. (February 2008). "TOWARD A SELECTION THEORY OF MOLECULAR EVOLUTION". Evolution. 62 (2): 255–265. doi:10.1111/j.1558-5646.2007.00308.x. PMID 18302709.
- ↑ Hershberg, Ruth; Petrov, Dmitri A. (December 2008). "Selection on Codon Bias". Annual Review of Genetics. 42 (1): 287–299. doi:10.1146/annurev.genet.42.110807.091442. PMID 18983258.
- ↑ Kimura, M. (1983). The Neutral Theory of Molecular Evolution. Cambridge University Press, Cambridge. ISBN 0-521-23109-4.
- ↑ Kimura, Motoo (1968). "Evolutionary rate at the molecular level" (PDF). Nature. 217 (5129): 624–626. Bibcode:1968Natur.217..624K. doi:10.1038/217624a0. PMID 5637732.
- ↑ King, J.L. & Jukes, T.H. (1969). "Non-Darwinian Evolution" (PDF). Science. 164 (3881): 788–798. Bibcode:1969Sci...164..788L. doi:10.1126/science.164.3881.788. PMID 5767777.
- 1 2 3 4 Akashi, H. "Weak Selection and Protein Evolution". Genetics. 192 (1): 15–31. doi:10.1534/genetics.112.140178.
- 1 2 3 4 5 6 Fay, JC, Wu, CI (2003). "Sequence divergence, functional constraint, and selection in protein evolution". Annu. Rev. Genom. Hum. Genet. 4: 213–35.
- ↑ Nachman M. (2006). C.W. Fox; J.B. Wolf, eds. ""Detecting selection at the molecular level" in: Evolutionary Genetics: concepts and case studies": 103–118.
- ↑ The nearly neutral theory expanded the neutralist perspective, suggesting that several mutations are nearly neutral, which means both random drift and natural selection is relevant to their dynamics.
- 1 2 3 4 Ohta, T (1992). Missing or empty
|title=(help) - ↑ Nei, M. (2005). "Selectionism and Neutralism in Molecular Evolution". Molecular Biology and Evolution. 22 (12): 2318–2342. doi:10.1093/molbev/msi242. PMC 1513187. PMID 16120807.
- ↑ Sueoka, N. (1964). "On the evolution of informational macromolecules". In Bryson, V.; Vogel, H.J. Evolving genes and proteins. Academic Press, New-York. pp. 479–496.
- ↑ Lahr, D. J.; Laughinghouse, H. D.; Oliverio, A. M.; Gao, F.; Katz, L. A. (2014). "How discordant morphological and molecular evolution among microorganisms can revise our notions of biodiversity on Earth". BioEssays. 36 (10): 950–959. doi:10.1002/bies.201400056. PMID 25156897.
Further reading
- Li, W.-H. (2006). Molecular Evolution. Sinauer. ISBN 0-87893-480-4.
- Lynch, M. (2007). The Origins of Genome Architecture. Sinauer. ISBN 0-87893-484-7.
- A. Meyer (Editor), Y. van de Peer, "Genome Evolution: Gene and Genome Duplications and the Origin of Novel Gene Functions", 2003, ISBN 978-1-4020-1021-7
- T. Ryan Gregory, "The Evolution of the Genome", 2004, YSBN 978-0123014634
| Evolution | |
|---|---|
| Population genetics | |
| Development | |
| Evolution of taxa | |
| Evolution of organs | |
| Evolution of processes | |
| Tempo and modes | |
| Modes of speciation | |
| History | |
| Related |
|
| |