Cache coherence
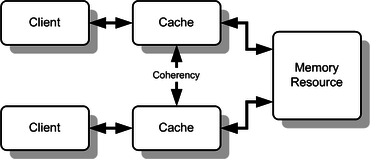
In computer science, cache coherence or cache coherency is the consistency of shared resource data that ends up stored in multiple local caches. When clients in a system maintain caches of a common memory resource, problems may arise with inconsistent data, which is particularly the case with CPUs in a multiprocessing system.
In the illustration on the right, if the client on the top has a copy of a memory block from a previous read and the client on the bottom changes that memory block, the client on the top could be left with an invalid cache of memory without any notification of the change. Cache coherence is intended to manage such conflicts and maintain consistency between the cache and memory.
Overview
In a shared memory multiprocessor system with a separate cache memory for each processor, it is possible to have many copies of any one instruction operand: one copy in the main memory and one in each cache memory. When one copy of an operand is changed, the other copies of the operand must be changed also. Cache coherence is the discipline that ensures that changes in the values of shared operands are propagated throughout the system in a timely fashion.[1]:30
There are three distinct levels of cache coherence:[2]
- Every write operation appears to occur instantaneously.
- All processors see exactly the same sequence of changes of values for each separate operand.
- Different processors may see an operand assume different sequences of values; this is considered to be a noncoherent behavior.
Definition
Coherence defines the behavior of reads and writes to the same memory location. The coherence of caches is obtained if the following conditions are met:[3]
- In a read made by a processor P to a location X that follows a write by the same processor P to X, with no writes to X by another processor occurring between the write and the read instructions made by P, X must always return the value written by P. This condition is related with the program order preservation, and this must be achieved even in monoprocessed architectures.
- A read made by a processor P1 to location X that happens after a write by another processor P2 to X must return the written value made by P2 if no other writes to X made by any processor occur between the two accesses and the read and write are sufficiently separated. This condition defines the concept of coherent view of memory. If processors can read the same old value after the write made by P2, we can say that the memory is incoherent.
- Writes to the same location must be sequenced. In other words, if location X received two different values A and B, in this order, from any two processors, the processors can never read location X as B and then read it as A. The location X must be seen with values A and B in that order.[2]
These conditions are defined supposing that the read and write operations are made instantaneously. However, this does not happen in computer hardware given the memory latency and other aspects of the architecture. A write by processor P1 may not be seen by a read from processor P2 if the read is made within a very small time after the write has been made. The memory consistency model defines when a written value must be seen by a following read instruction made by the other processors.
The alternative definition of a coherent system is via the definition of sequential consistency memory model: "the cache coherent system must appear to execute all threads’ loads and stores to a single memory location in a total order that respects the program order of each thread".[4] Thus, the only difference between the cache coherent system and sequentially consistent system is in the number of address locations the definition talks about (single memory location for a cache coherent system, and all memory locations for a sequentially consistent system).
Another definition is: "a multiprocessor is cache consistent if all writes to the same memory location are performed in some sequential order".[5]
Rarely, and especially in algorithms, coherence can instead refer to the locality of reference.
Coherence mechanisms
- Directory-based
- In a directory-based system, the data being shared is placed in a common directory that maintains the coherence between caches. The directory acts as a filter through which the processor must ask permission to load an entry from the primary memory to its cache. When an entry is changed, the directory either updates or invalidates the other caches with that entry.
- Snooping
- First introduced in 1983,[6] snooping is a process where the individual caches monitor address lines for accesses to memory locations that they have cached.[7] It is called a write invalidate protocol when a write operation is observed to a location that a cache has a copy of and the cache controller invalidates its own copy of the snooped memory location.[8]
- Snarfing
- It is a mechanism where a cache controller watches both address and data in an attempt to update its own copy of a memory location when a second master modifies a location in main memory. When a write operation is observed to a location that a cache has a copy of, the cache controller updates its own copy of the snarfed memory location with the new data.
Distributed shared memory systems mimic these mechanisms in an attempt to maintain consistency between blocks of memory in loosely coupled systems.
The two most common mechanisms of ensuring coherency are snooping and directory-based, each having its own benefits and drawbacks. Snooping protocols tend to be faster, if enough bandwidth is available, since all transactions are a request/response seen by all processors. The drawback is that snooping isn't scalable. Every request must be broadcast to all nodes in a system, meaning that as the system gets larger, the size of the (logical or physical) bus and the bandwidth it provides must grow. Directories, on the other hand, tend to have longer latencies (with a 3 hop request/forward/respond) but use much less bandwidth since messages are point to point and not broadcast. For this reason, many of the larger systems (>64 processors) use this type of cache coherence.
For the snooping mechanism, a snoop filter reduces the snooping traffic by maintaining a plurality of entries, each representing a cache line that may be owned by one or more nodes. When replacement of one of the entries is required, the snoop filter selects for replacement the entry representing the cache line or lines owned by the fewest nodes, as determined from a presence vector in each of the entries. A temporal or other type of algorithm is used to refine the selection if more than one cache line is owned by the fewest number of nodes.[9]
Coherency protocols
Distributed shared memory systems employ coherency protocols to ensure the consistency between all caches, by maintaining memory coherence according to a specific consistency model. Older multiprocessors support the sequential consistency model, while modern shared memory systems typically support the release consistency or weak consistency models.
Transitions between states in any specific implementation of these protocols may vary. For example, an implementation may choose different update and invalidation transitions such as update-on-read, update-on-write, invalidate-on-read, or invalidate-on-write. The choice of transition may affect the amount of inter-cache traffic, which in turn may affect the amount of cache bandwidth available for actual work. This should be taken into consideration in the design of distributed software that could cause strong contention between the caches of multiple processors.
Various models and protocols have been devised for maintaining coherence, such as MSI, MESI (aka Illinois), MOSI, MOESI, MERSI, MESIF, write-once, and Synapse, Berkeley, Firefly and Dragon protocol.[1]:30–34 In 2011, ARM Ltd proposed the AMBA 4 ACE[10] for handling coherency in SoCs.
See also
References
- 1 2 Michael E. Thomadakis (2011-03-17). "The Architecture of the Nehalem Processor and Nehalem-EP SMP Platforms" (PDF). Texas A&M University. Retrieved 2014-03-21.
- 1 2 Neupane, Mahesh (April 16, 2004). "Cache Coherence" (PDF). Archived from the original (PDF) on 20 June 2010.
- ↑ Patterson & Hennessy 2012, pp. 352-353.
- ↑ Sorin, Hill & Wood 2011.
- ↑ Steinke & Nutt.
- ↑ Ravishankar, Chinya; Goodman, James (February 28, 1983). "Cache Implementation for Multiple Microprocessors" (PDF). Proceedings of IEEE COMPCON: 346–350.
- ↑ Patterson & Hennessy 2009, p. 536.
- ↑ Patterson & Hennessy 2009, pp. 536-537.
- ↑ Rasmus Ulfsnes (June 2013). "Design of a Snoop Filter for Snoop-Based Cache Coherency Protocols" (PDF). diva-portal.org. Norwegian University of Science and Technology. Retrieved 2014-01-20.
- ↑ Kriouile, A., & Serwe, W. (2013). Formal Analysis of the ACE Specification for Cache Coherent Systems-on-Chip. In Formal Methods for Industrial Critical Systems (pp. 108-122). Springer Berlin Heidelberg., ISBN 978-3-642-41010-9
Further reading
- Patterson, David; Hennessy, John (2009). Computer Organization and Design (4th ed.). Morgan Kaufmann. ISBN 978-0-12-374493-7.
- Handy, Jim (1998). The Cache Memory Book (2nd ed.). Morgan Kaufmann. ISBN 9780123229809.
- Sorin, Daniel; Hill, Mark; Wood, David (2011). A Primer on Memory Consistency and Cache Coherence (PDF). Morgan and Claypool. ISBN 978-1608455645.
- Steinke, Robert C.; Nutt, Gary J. (1 September 2004). "A unified theory of shared memory consistency". Journal of the ACM. 51 (5): 800–849. doi:10.1145/1017460.1017464.
| General | |
|---|---|
| Levels | |
| Multithreading | |
| Theory | |
| Elements | |
| Coordination | |
| Programming | |
| Hardware | |
| APIs | |
| Problems | |
| |