Structural equation modeling
Structural equation modeling (SEM) refers to a diverse set of mathematical models, computer algorithms, and statistical methods that fit networks of constructs to data.[1] SEM includes confirmatory factor analysis, path analysis, partial least squares path analysis, LISREL and latent growth modeling.[2] The concept should not be confused with the related concept of structural models in econometrics, nor with structural models in economics. Structural equation models are often used to assess unobservable 'latent' constructs. They often invoke a measurement model that defines latent variables using one or more observed variables, and a structural model that imputes relationships between latent variables.[1] [3] The links between constructs of a structural equation model may be estimated with independent regression equations or through more involved approaches such as those employed in LISREL.[4]
Use of SEM is commonly justified in the social sciences because of its ability to impute relationships between unobserved constructs (latent variables) from observable variables.[5] To provide a simple example, the concept of human intelligence cannot be measured directly as one could measure height or weight. Instead, psychologists develop a hypothesis of intelligence and write measurement instruments with items (questions) designed to measure intelligence according to their hypothesis.[6] They would then use SEM to test their hypothesis using data gathered from people who took their intelligence test. With SEM, "intelligence" would be the latent variable and the test items would be the observed variables.
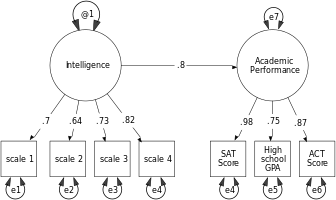
A simplistic model suggesting that intelligence (as measured by four questions) can predict academic performance (as measured by SAT, ACT, and high school GPA) is shown below. In SEM diagrams, latent variables are commonly shown as ovals and observed variables as rectangles. The below diagram shows how error (e) influences each intelligence question and the SAT, ACT, and GPA scores, but does not influence the latent variables. SEM provides numerical estimates for each of the parameters (arrows) in the model to indicate the strength of the relationships. Thus, in addition to testing the overall theory, SEM therefore allows the researcher to diagnose which observed variables are good indicators of the latent variables.[7]
Various methods in structural equation modeling have been used in the sciences,[8] business,[9] education,[10] and other fields. Use of SEM methods in analysis is controversial because SEM methods generally lack widely accepted goodness-of-fit statistics and most SEM software offers little latitude for error analysis. This puts SEM at a disadvantage with respect to systems of regression equation methods, though the latter are limited in their ability to fit unobserved 'latent' constructs.
History
Structural equation modeling, as the term is currently used in sociology, psychology, and other social sciences evolved from the earlier methods in genetic path modeling of Sewall Wright. Their modern forms came about with computer intensive implementations in the 1960s and 1970s. SEM evolved in three different streams: (1) systems of equation regression methods developed mainly at the Cowles Commission; (2) iterative maximum likelihood algorithms for path analysis developed mainly by Karl Gustav Jöreskog at the Educational Testing Service and subsequently at the University of Uppsala; and (3) iterative canonical correlation fit algorithms for path analysis also developed at the University of Uppsala by Hermann Wold. Much of this development occurred at a time that automated computing was offering substantial upgrades over the existing calculator and analogue computing methods available, themselves products of the proliferation of office equipment innovations in the late 19th century. The text Structural Equation Modeling: From Paths to Networks, New York: Springer, 2015 provides a complete history of the methods (Westland, 2015)[11]
Loose and confusing terminology has been used to obscure weaknesses in the methods. In particular, PLS-PA (the Lohmoller algorithm) has been conflated with partial least squares regression PLSR, which is a substitute for ordinary least squares regression and has nothing to do with path analysis. PLS-PA has been falsely promoted as a method that works with small datasets when other estimation approaches fail. Westland (2010) decisively showed this not to be true and developed an algorithm for sample sizes in SEM. Since the 1970s the 'small sample size' assertion has been known to be false; e.g. see (Dhrymes, 1972, 1974; Dhrymes & Erlat, 1972; Dhrymes et al., 1972; Gupta, 1969; Sobel, 1982)
Both LISREL and PLS-PA were conceived as iterative computer algorithms, with an emphasis from the start on creating an accessible graphical and data entry interface and extension of Wright’s (1921) path analysis. Early Cowles’ Commission work on simultaneous equations estimation centered on Koopman and Hood’s (1953) algorithms from the economics of transportation and optimal routing, with maximum likelihood estimation, and closed form algebraic calculations, as iterative solution search techniques were limited in the days before computers. Anderson and Rubin (1949, 1950) developed the limited information maximum likelihood estimator for the parameters of a single structural equation, which indirectly included the two-stage least squares estimator and its asymptotic distribution (Anderson, 2005) and Farebrother (1999). Two-stage least squares was originally proposed as a method of estimating the parameters of a single structural equation in a system of linear simultaneous equations, being introduced by Theil (1953a, 1953b, 1961) and more or less independently by Basmann (1957) and Sargan (1958). Anderson’s limited information maximum likelihood estimation was eventually implemented in a computer search algorithm, where it competed with other iterative SEM algorithms. Of these, two-stage least squares was by far the most widely used method in the 1960s and the early 1970s.
Systems of regression equation approaches were developed at the Cowles Commission from the 1950s on, extending the transportation modeling of Tjalling Koopmans. Sewall Wright, and other statisticians attempted to promote path analysis methods at Cowles (then at the University of Chicago). University of Chicago statisticians identified many faults with path analysis applications to the social sciences; faults which did not pose significant problems for identifying gene transmission in Wright's context, but which made path methods such as PLS-PA and LISREL problematic in the social sciences. Freedman (1987) summarized these objections in path analyses': “failure to distinguish among causal assumptions, statistical implications, and policy claims has been one of the main reasons for the suspicion and confusion surrounding quantitative methods in the social sciences” (see also Wold’s (1987) response). Wright’s path analysis never gained a large following among U.S. econometricians, but was successful in influencing Hermann Wold and his student Karl Jöreskog. Jöreskog's student Claes Fornell promoted LISREL in the US.
Advances in computers made it simple for novices to apply structural equation methods in the computer-intensive analysis of large datasets in complex, unstructured problems. The most popular solution techniques fall into three classes of algorithms: (1) ordinary least squares algorithms applied independently to each path, such as applied in the so-called PLS path analysis packages which estimate with OLS; (2) covariance analysis algorithms evolving from seminal work by Wold and his student Karl Jöreskog implemented in LISREL, AMOS, and EQS; and (3) simultaneous equations regression algorithms developed at the Cowles Commission by Tjalling Koopmans.
Pearl [12] has extended SEM from linear to nonparametric models, and proposed causal and counterfactual interpretations of the equations. For example, excluding a variable Z from the arguments of an equation asserts that the dependent variable is independent of interventions on the excluded variable, once we hold constant the remaining arguments. Nonparametric SEMs permit the estimation of total, direct and indirect effects without making any commitment to the form of the equations or to the distributions of the error terms. This extends mediation analysis to systems involving categorical variables in the presence of nonlinear interactions. Bollen and Pearl[13] survey the history of the causal interpretation of SEM and why it has become a source of confusions and controversies.
SEM path analysis methods are popular in the social sciences because of their accessibility; packaged computer programs allow researchers to obtain results without the inconvenience of understanding experimental design and control, effect and sample sizes, and numerous other factors that are part of good research design. Supporters say that this reflects a holistic, and less blatantly causal, interpretation of many real world phenomena – especially in psychology and social interaction – than may be adopted in the natural sciences; detractors suggest that many flawed conclusions have been drawn because of this lack of experimental control.
Direction in the directed network models of SEM arises from presumed cause-effect assumptions made about reality. Social interactions and artifacts are often epiphenomena – secondary phenomena that are difficult to directly link to causal factors. An example of a physiological epiphenomenon is, for example, time to complete a 100-meter sprint. I may be able to improve my sprint speed from 12 seconds to 11 seconds – but I will have difficulty attributing that improvement to any direct causal factors, like diet, attitude, weather, etc. The 1 second improvement in sprint time is an epiphenomenon – the holistic product of interaction of many individual factors.
General approach to SEM
Although each technique in the SEM family is different, the following aspects are common to many SEM methods.
Model specification
Two main components of models are distinguished in SEM: the structural model showing potential causal dependencies between endogenous and exogenous variables, and the measurement model showing the relations between latent variables and their indicators. Exploratory and confirmatory factor analysis models, for example, contain only the measurement part, while path diagrams can be viewed as SEMs that contain only the structural part.
In specifying pathways in a model, the modeler can posit two types of relationships: (1) free pathways, in which hypothesized causal (in fact counterfactual) relationships between variables are tested, and therefore are left 'free' to vary, and (2) relationships between variables that already have an estimated relationship, usually based on previous studies, which are 'fixed' in the model.
A modeler will often specify a set of theoretically plausible models in order to assess whether the model proposed is the best of the set of possible models. Not only must the modeler account for the theoretical reasons for building the model as it is, but the modeler must also take into account the number of data points and the number of parameters that the model must estimate to identify the model. An identified model is a model where a specific parameter value uniquely identifies the model, and no other equivalent formulation can be given by a different parameter value. A data point is a variable with observed scores, like a variable containing the scores on a question or the number of times respondents buy a car. The parameter is the value of interest, which might be a regression coefficient between the exogenous and the endogenous variable or the factor loading (regression coefficient between an indicator and its factor). If there are fewer data points than the number of estimated parameters, the resulting model is "unidentified", since there are too few reference points to account for all the variance in the model. The solution is to constrain one of the paths to zero, which means that it is no longer part of the model.
Estimation of free parameters
Parameter estimation is done by comparing the actual covariance matrices representing the relationships between variables and the estimated covariance matrices of the best fitting model. This is obtained through numerical maximization of a fit criterion as provided by maximum likelihood estimation, quasi-maximum likelihood estimation, weighted least squares or asymptotically distribution-free methods. This is often accomplished by using a specialized SEM analysis program, of which several exist.
Assessment of model and model fit
Having estimated a model, analysts will want to interpret the model. Estimated paths may be tabulated and/or presented graphically as a path model. The impact of variables is assessed using path tracing rules (see path analysis).
It is important to examine the "fit" of an estimated model to determine how well it models the data. This is a basic task in SEM modeling: forming the basis for accepting or rejecting models and, more usually, accepting one competing model over another. The output of SEM programs includes matrices of the estimated relationships between variables in the model. Assessment of fit essentially calculates how similar the predicted data are to matrices containing the relationships in the actual data.
Formal statistical tests and fit indices have been developed for these purposes. Individual parameters of the model can also be examined within the estimated model in order to see how well the proposed model fits the driving theory. Most, though not all, estimation methods make such tests of the model possible.
Of course as in all statistical hypothesis tests, SEM model tests are based on the assumption that the correct and complete relevant data have been modeled. In the SEM literature, discussion of fit has led to a variety of different recommendations on the precise application of the various fit indices and hypothesis tests.
There are differing approaches to assessing fit. Traditional approaches to modeling start from a null hypothesis, rewarding more parsimonious models (i.e. those with fewer free parameters), to others such as AIC that focus on how little the fitted values deviate from a saturated model (i.e. how well they reproduce the measured values), taking into account the number of free parameters used. Because different measures of fit capture different elements of the fit of the model, it is appropriate to report a selection of different fit measures. Guidelines (i.e., "cutoff scores") for interpreting fit measures, including the ones listed below, are the subject of much debate among SEM researchers.[14]
Some of the more commonly used measures of fit include:
- Chi-Squared A fundamental measure of fit used in the calculation of many other fit measures. Conceptually it is a function of the sample size and the difference between the observed covariance matrix and the model covariance matrix.
- Akaike information criterion (AIC)
- A test of relative model fit: The preferred model is the one with the lowest AIC value.
- where k is the number of parameters in the statistical model, and L is the maximized value of the likelihood of the model.
- Root Mean Square Error of Approximation (RMSEA)
- Standardized Root Mean Residual (SRMR)
- The SRMR is a popular absolute fit indicator. Hu and Bentler (1999) suggested .08 or smaller as a guideline for good fit.[19]
- Comparative Fit Index (CFI)
- In examining baseline comparisons, the CFI depends in large part on the average size of the correlations in the data. If the average correlation between variables is not high, then the CFI will not be very high. A CFI value of .95 or higher is desirable.[19]

For each measure of fit, a decision as to what represents a good-enough fit between the model and the data must reflect other contextual factors such as sample size, the ratio of indicators to factors, and the overall complexity of the model. For example, very large samples make the Chi-squared test overly sensitive and more likely to indicate a lack of model-data fit. [20])
Model modification
The model may need to be modified in order to improve the fit, thereby estimating the most likely relationships between variables. Many programs provide modification indices which may guide minor modifications. Modification indices report the change in χ² that result from freeing fixed parameters: usually, therefore adding a path to a model which is currently set to zero. Modifications that improve model fit may be flagged as potential changes that can be made to the model. Modifications to a model, especially the structural model, are changes to the theory claimed to be true. Modifications therefore must make sense in terms of the theory being tested, or be acknowledged as limitations of that theory. Changes to measurement model are effectively claims that the items/data are impure indicators of the latent variables specified by theory.[21]
Models should not be led by MI, as Maccallum (1986) demonstrated: "even under favorable conditions, models arising from specification searches must be viewed with caution."[22]
Sample size and power
While researchers agree that large sample sizes are required to provide sufficient statistical power and precise estimates using SEM, there is no general consensus on the appropriate method for determining adequate sample size.[23][24] Generally, the considerations for determining sample size include the number of observations per parameter, the number of observations required for fit indexes to perform adequately, and the number of observations per degree of freedom.[23] Researchers have proposed guidelines based on simulation studies (Chou & Bentler, 1995),[25] professional experience (Bentler and Chou, 1987),[26] and mathematical formulas (MacCallum, Browne, and Sugawara, 1996; Westland, 2010).[24][27]
Sample size requirements to achieve a particular significance and power in SEM hypothesis testing are similar for the same model when any of the three algorithms (PLS-PA, LISREL or systems of regression equations) are used for testing.
Interpretation and communication
The set of models are then interpreted so that claims about the constructs can be made, based on the best fitting model.
Caution should always be taken when making claims of causality even when experimentation or time-ordered studies have been done. The term causal model must be understood to mean: "a model that conveys causal assumptions," not necessarily a model that produces validated causal conclusions. Collecting data at multiple time points and using an experimental or quasi-experimental design can help rule out certain rival hypotheses but even a randomized experiment cannot rule out all such threats to causal inference. Good fit by a model consistent with one causal hypothesis invariably entails equally good fit by another model consistent with an opposing causal hypothesis. No research design, no matter how clever, can help distinguish such rival hypotheses, save for interventional experiments.[12]
As in any science, subsequent replication and perhaps modification will proceed from the initial finding.
Advanced uses
- Measurement invariance
- Multiple group modelling: This is a technique allowing joint estimation of multiple models, each with different sub-groups. Applications include behavior genetics, and analysis of differences between groups (e.g., gender, cultures, test forms written in different languages, etc.).
- Latent growth modeling
- Hierarchical/multilevel models; item response theory models
- Mixture model (latent class) SEM
- Alternative estimation and testing techniques
- Robust inference
- Survey sampling analyses
- Multi-method multi-trait models
- Structural Equation Model Trees
SEM-specific software
Several software packages exists for fitting structural equation models. LISREL was the first such software, initially released in the 1970s. Other standalone packages include Mplus , Mx , EQS and the open source Onyx . The Amos SPSS extension can fit structural equation models .
There are also several packages for the R open source statistical environment. The packages sem , lava and lavaan can fit general structural equation models. Bayesian SEM estimation is implemented in the blavaan package , which relies on the JAGS package for the Bayesian computations. The sparseSEM and regsem packages provides regularized (lasso and ridge regression like) estimation procedures.
The OpenMx R package provides an open source and enhanced version of the Mx application .
Scholars consider it good practice to report which software package and version was used for SEM analysis because they have different capabilities and may use slightly different methods to perform similarly-named techniques.[28]
See also
- Graphical model
- Simultaneous equations model
- Multivariate statistics
- Partial least squares regression
- Partial least squares path modeling
References
- 1 2 Kaplan 2007, p. 79-88.
- ↑ Kline 2011.
- ↑ Kline 2011, p. 230-294.
- ↑ Kline 2011, p. 265-294.
- ↑ Hancock, Gregory. "Fortune Cookies, Measurement Error, and Experimental Design". Journal of Modern Applied Statistical Methods. 2 (2): 293–305. Retrieved 24 January 2015.
- ↑ Thorndike, Robert (2007). "Intelligence Tests". In Salkind, Neil. Encyclopedia of Measurement and Statistics. Sage. pp. 477–480. ISBN 9781412952644.
- ↑ MacCallum & Austin 2000, p. 209.
- ↑ Gillespie, David; Perron, Brian (2007). "Structural Equation Modeling". In Boslaugh, Sarah. Encyclopedia of Epidemiology. Sage. pp. 1005–1009. ISBN 9781412953948.
- ↑ Markus, Keith (2007). "Structural Equation Modeling". In Rogelberg, Steve. Encyclopedia of Industrial and Organizational Psychology. Sage. pp. 774–777. ISBN 9781412952651.
- ↑ Shelley, Mack (2007). "Structural Equation Modeling". In English, Fenwick. Encyclopedia of Educational Leadership and Administration. Sage. ISBN 9781412939584.
- ↑ Westland, J. Christopher (2015). Structural Equation Modeling: From Paths to Networks. New York: Springer.
- 1 2 Pearl, Judea (2000). Causality: Models, Reasoning, and Inference. Cambridge University Press. ISBN 0-521-77362-8.
- ↑ Bollen, K.A.; Pearl, J. (2013). "Eight Myths about Causality and Structural Equation Models". In Morgan, S.L. Handbook of Causal Analysis for Social Research. Dordrecht: Springer. pp. 301–328.
- ↑ MacCallum & Austin 2000, p. 218-219.
- ↑ Kline 2011, p. 205.
- ↑ Kline 2011, p. 206.
- ↑ Hu & Bentler 1999, p. 11.
- ↑ Browne, M. W.; Cudeck, R. (1993). "Alternative ways of assessing model fit". In Bollen, K. A.; Long, J. S. Testing structural equation models. Newbury Park, CA: Sage.
- 1 2 Hu & Bentler 1999, p. 27.
- ↑ Kline 2011, p. 201.
- ↑ Loehlin, J. C. (2004). Latent Variable Models: An Introduction to Factor, Path, and Structural Equation Analysis. Psychology Press.
- ↑ MacCallum, R. (1986). Specification searches in covariance structure modeling. Psychological Bulletin, 100, 107-120. doi
- 1 2 Quintana & Maxwell 1999, p. 499.
- 1 2 Westland, J. Christopher (2010). "Lower bounds on sample size in structural equation modeling". Electron. Comm. Res. Appl. 9 (6): 476–487. doi:10.1016/j.elerap.2010.07.003.
- ↑ Chou, C. P.; Bentler, Peter (1995). "Estimates and tests in structural equation modeling". In Hoyle, Rick. Structural equation modeling: Concepts, issues, and applications. Thousand Oaks, CA: Sage. pp. 37–55.
- ↑ Bentler, Peter; Chou, C.-P. (1987). "Practical issues in structural equation modeling". Sociological Methods and Research. 16: 78–117.
- ↑ MacCallum, R. C.; Browne, M.; Sugawara, H. (1996). "Power analysis and determination of sample size for covariance structural modeling" (PDF). Psychological Methods. 1 (2): 130–149. doi:10.1037/1082-989X.1.2.130. Retrieved 24 January 2015.
- ↑ Kline 2011, p. 79-88.
Further reading
- Bagozzi, R.; Yi, Y. (2012) "Specification, evaluation, and interpretation of structural equation models". Journal of the Academy of Marketing Science, 40 (1), 8–34. doi:10.1007/s11747-011-0278-x
- Bartholomew, D. J., and Knott, M. (1999) Latent Variable Models and Factor Analysis Kendall's Library of Statistics, vol. 7, Edward Arnold Publishers, ISBN 0-340-69243-X
- Bentler, P.M. & Bonett, D.G. (1980), "Significance tests and goodness of fit in the analysis of covariance structures", Psychological Bulletin, 88, 588-606.
- Bollen, K. A. (1989). Structural Equations with Latent Variables. Wiley, ISBN 0-471-01171-1
- Byrne, B. M. (2001) Structural Equation Modeling with AMOS - Basic Concepts, Applications, and Programming.LEA, ISBN 0-8058-4104-0
- Goldberger, A. S. (1972). Structural equation models in the social sciences. Econometrica 40, 979- 1001.
- Haavelmo, T. (1943), "The statistical implications of a system of simultaneous equations," Econometrica 11:1–2. Reprinted in D.F. Hendry and M.S. Morgan (Eds.), The Foundations of Econometric Analysis, Cambridge University Press, 477—490, 1995.
- Hair, J. F.; Hult, G. T. M.; Ringle, C. M.; Sarstedt, M. (2014). A Primer on Partial Least Squares Structural Equation Modeling (PLS-SEM). Thousand Oaks, CA: Sage. ISBN 9781452217444.
- Hoyle, R H (ed) (1995) Structural Equation Modeling: Concepts, Issues, and Applications. SAGE, ISBN 0-8039-5318-6
- Hu, L.; Bentler, Peter (1999). "Cutoff criteria for fit indexes in covariance structure analysis: Conventional criteria versus new alternatives". Structural Equation Modeling. 6 (1): 1–55. doi:10.1080/10705519909540118.
- Jöreskog, K.; F. Yang (1996). "Non-linear structural equation models: The Kenny-Judd model with interaction effects". In G. Marcoulides and R. Schumacker, (eds.), Advanced structural equation modeling: Concepts, issues, and applications. Thousand Oaks, CA: Sage Publications.
- Kaplan, D. (2000), Structural Equation Modeling: Foundations and Extensions SAGE, Advanced Quantitative Techniques in the Social Sciences series, vol. 10, ISBN 0-7619-1407-2
- Kaplan, David (2007). Structural Equation Modeling. Sage. pp. 1089–1093. ISBN 9781412950589.
- Kline, Rex (2011). Principles and Practice of Structural Equation Modeling (Third ed.). Guilford. ISBN 9781606238769.
- MacCallum, Robert; Austin, James (2000). "Applications of Structural Equation Modeling in Psychological Research" (PDF). Annual Review of Psychology. 51: 201–226. doi:10.1146/annurev.psych.51.1.201. Retrieved 25 January 2015.
- Schermelleh-Engel, K.; Moosbrugger, H.; Müller, H. (2003), "Evaluating the fit of structural equation models" (PDF), Methods of Psychological Research, 8 (2): 23–74.
- Westland, J. Christopher (2010) Lower Bounds on Sample Size in Structural Equation Modeling, Electronic Commerce Research and Applications, Dec 2010, PII:S1567-4223(10)00054-2, DOI: 10.1016/j.elerap.2010.07.003
- Westland, J. Christopher (2015). Structural Equation Modeling: From Paths to Networks. New York: Springer.
External links
- Ed Rigdon's Structural Equation Modeling Page: people, software and sites
- Structural equation modeling page under David Garson's StatNotes, NCSU
- Issues and Opinion on Structural Equation Modeling, SEM in IS Research
- The causal interpretation of structural equations (or SEM survival kit) by Judea Pearl 2000.
- Structural Equation Modeling Reference List by Jason Newsom: journal articles and book chapters on structural equation models
- PLS-SEM book: online resources and additional information
- Path Analysis in AFNI: The open source (GPL) AFNI package contains SEM code
- Handbook of Management Scales, a collection of previously used multi-item scales to measure constructs for SEM
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||
| |||||||||||||||||||||||||||||||||||||||||||||