MIPS instruction set
| Designer | MIPS Technologies, Inc. |
|---|---|
| Bits | 64-bit (32→64) |
| Introduced | 1981 |
| Design | RISC |
| Type | Register-Register |
| Encoding | Fixed |
| Branching | Compare and branch |
| Endianness | Bi |
| Extensions | MDMX, MIPS-3D |
| Registers | |
| General purpose | 31 plus always-zero R0 |
| Floating point | 32 (paired DP for 32-bit) |
MIPS (originally an acronym for Microprocessor without Interlocked Pipeline Stages) is a reduced instruction set computer (RISC) instruction set architecture (ISA) developed by MIPS Technologies (formerly MIPS Computer Systems, Inc.). The early MIPS architectures were 32-bit, with 64-bit versions added later. Multiple revisions of the MIPS instruction set exist, including MIPS I, MIPS II, MIPS III, MIPS IV, MIPS V, MIPS32, and MIPS64. The current revisions are MIPS32 (for 32-bit implementations) and MIPS64 (for 64-bit implementations).[1][2] MIPS32 and MIPS64 define a control register set as well as the instruction set.
Several optional extensions are also available, including MIPS-3D which is a simple set of floating-point SIMD instructions dedicated to common 3D tasks,[3] MDMX (MaDMaX) which is a more extensive integer SIMD instruction set using the 64-bit floating-point registers, MIPS16e which adds compression to the instruction stream to make programs take up less room,[4] and MIPS MT, which adds multithreading capability.[5]
Computer architecture courses in universities and technical schools often study the MIPS architecture.[6] The architecture greatly influenced later RISC architectures such as Alpha.
MIPS implementations are primarily used in embedded systems such as Windows CE devices, routers, residential gateways, and video game consoles such as the Nintendo 64, Sony PlayStation, PlayStation 2 and PlayStation Portable. It used to be popular in supercomputers but all such systems have dropped off the TOP500 list. Until late 2006, they were also used in many of SGI's computer products. MIPS implementations were also used by Digital Equipment Corporation, NEC, Pyramid Technology, Siemens Nixdorf, Tandem Computers and others during the late 1980s and 1990s. In the mid to late 1990s, it was estimated that one in three RISC microprocessors produced was a MIPS implementation.[7] Windows NT supported MIPS until the release of Windows NT 4.0 SP3 in 1997.
MIPS is a modular architecture supporting up to four coprocessors (COP0/1/2/3). In MIPS terminology, COP0 is the System Control Coprocessor (main part of the CPU), COP1 is an optional FPU and COP2/COP3 are undefined optional coprocessors. For example, in the original Playstation game console, COP0 is the System Control Coprocessor and COP2 is a Generic Tile Engine. In the Playstation 2 game console, COP0 is a Toshiba R5900 chip, COP1 is a FPU and COP2 is VPU0.
Versions of the MIPS instruction set
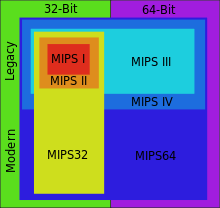
MIPS is a load-store architecture (also sometimes called 'register-register'), meaning it only performs arithmetic and logic operations between CPU registers, requiring load/store instructions to access memory (as opposed to a register memory architecture).
Processors based upon the MIPS instruction set have been in production since 1988. Over time several enhancements of the instruction set were made. The different revisions which have been introduced are MIPS I, MIPS II, MIPS III, MIPS IV and MIPS V. Each revision is a superset of its predecessors. When MIPS Technologies was spun out of Silicon Graphics again in 1998, they refocused on the embedded market. At that time, this superset property was found to be a problem, and the architecture definition was changed to define a 32-bit MIPS32 and a 64-bit MIPS64 instruction set.
MIPS I
Introduced in 1985 with the R2000.
MIPS II
Introduced in 1990 with the R6000.
MIPS III
Introduced in 1992 in the R4000. It adds 64-bit registers and integer instructions and a floating point square root instruction.
MIPS IV
MIPS IV is the fourth version of the architecture. It is a superset of MIPS III and is compatible with all existing versions of MIPS. The first implementation of MIPS IV was the R8000, which was introduced in 1994. MIPS IV added:
- Register + register addressing for floating point loads and stores
- Single- and double-precision floating point fused-multiply adds and subtracts
- Conditional move instructions for both integer and floating-point
- Extra condition bits in the floating point control and status register, bringing the total to eight
MIPS V
Announced on October 21, 1996 at the Microprocessor Forum 1996.[8] MIPS V was designed to improve the performance of 3D graphics applications. In the mid-1990s, a major use of non-embedded MIPS microprocessors were graphics workstations from SGI. MIPS V was complemented by the integer-only MIPS Digital Media Extensions (MDMX) multimedia extensions, which were announced on the same date as MIPS V.[9]
MIPS V implementations were never introduced. In 1997, SGI announced the "H1" or "Beast" and the "H2" or "Capitan" microprocessors. The former was to have been the first MIPS V implementation, and was due to be introduced in 1999. The "H1" and "H2" projects were later combined and were eventually canceled in 1998.
MIPS V added a new data type, the pair-single (PS), which consisted of two single-precision (32-bit) floating-point numbers stored in the existing 64-bit floating-point registers. Variants of existing floating-point instructions for arithmetic, compare and conditional move were added to operate on this data type in a SIMD fashion. New instructions were added for loading, rearranging and converting PS data. It was the first instruction set to exploit floating-point SIMD with existing resources.[9]
MIPS32/MIPS64
The 32-bit MIPS32 instruction set and the 64-bit MIPS64 instruction set were introduced in 1999.[10] MIPS32 is based on MIPS II with some additional features from MIPS III, MIPS IV, and MIPS V; MIPS64 is based on MIPS V.[10] NEC, Toshiba and SiByte (later acquired by Broadcom) each obtained licenses for the MIPS64 instruction set as soon as it was announced. Philips, LSI Logic, IDT, Raza Microelectronics, Inc., Cavium, Loongson Technology and Ingenic Semiconductor have since joined them.
MIPS32/MIPS64 Release 1
The first release of MIPS32, based on the MIPS II instruction set, added conditional moves, prefetch instructions, and other features from the R4000 and R5000 families of 64-bit processors.[10] The first release of MIPS64 adds a MIPS32 mode to run 32-bit code.[10] The MUL and MADD (multiply-add) instructions, previously available in some implementations, were added to the MIPS32 and MIPS64 specifications, as were cache control instructions.[10]
MIPS32/MIPS64 Release 4 (skipped)
Skipped due to the number 4 being perceived as unlucky in the Asia Pacific Rim market.[11]
MIPS32/MIPS64 Release 5
Announced on December 6, 2012.[12]
MIPS32/MIPS64 Release 6
MIPS32/MIPS64 Release 6 in 2014 added[13] the following:
- a new family of branches with no delay slot:
- unconditional branches (BC) & branch-and-link (BALC) with a 26-bit offset,
- conditional branch on zero/non-zero with a 21-bit offset,
- full set of signed & unsigned conditional branches compare between two registers (e.g. BGTUC) or a register against zero (e.g. BGTZC),
- full set of branch-and-link which compare a register against zero (e.g. BGTZALC).
- index jump instructions with no delay slot designed to support large absolute addresses.
- instructions to load 16-bit immediates at bit position 16, 32 or 48, allowing to easily generate large constants.
- PC-relative load instructions, as well as address generation with large (PC-relative) offsets.
- bit-reversal & byte-alignement instructions (previously only available with the DSP extension).
- multiply & divide instructions redefined so that they use a single register for their result).
- instructions generating truth values now generate all zeroes or all ones instead of just clearing/setting the 0-bit,
- instructions using a truth value now only interpret all-zeroes as false instead of just looking at the 0-bit.
Removed infrequently used instructions:
- some conditional moves
- branch likely instructions (deprecated in previous releases).
- integer overflow trapping instructions with 16-bit immediate
- integer accumulator instructions (together HI/LO registers, moved to the DSP Application-Specific Extension)
- unaligned load instructions (LWL & LWR), (requiring that most ordinary loads & stores support misaligned access, possibly via trapping and with the addition of a new instruction (BALIGN))
Reorganized the instruction encoding, freeing space for future expansions.
Application-specific extensions
MIPS MCU ASE
Enhancements for microcontroller applications. The MCU ASE (Application Specific Extension) has been developed to extend the interrupt controller support, reduce the interrupt latency and enhance the I/O peripheral control function typically required in microcontroller system designs.
- Separate priority and vector generation
- Supports up to 256 interrupts in EIC (External Interrupt Controller) mode and eight hardware interrupt pins
- Provides 16-bit vector offset address
- Pre-fetching of the interrupt exception vector
- Automated Interrupt Prologue – adds hardware to save and update system status before the interrupt handling routine
- Automated Interrupt Epilogue – restores the system state previously stored in the stack for returning from the interrupt.
- Interrupt Chaining – supports the service of pending interrupts without the need to exit the initial interrupt routine, saving the cycles required to store and restore multiple active interrupts
- Supports speculative pre-fetching of the interrupt vector address. Reduces the number of interrupt service cycles by overlapping memory accesses with pipeline flushes and exception prioritization
- Includes atomic bit set/clear instructions which enables bits within an I/O register that are normally used to monitor or control external peripheral functions to be modified without interruption, ensuring the action is performed securely.
MIPS16e ASE
MIPS16e ASE (Application Specific Extension) is an optional extension to both the MIPS32 and MIPS64 architectures.
The MIPS16e ASE enables embedded system designers to reduce costs by decreasing the size of memory required to run their application by up to 40 percent compared to traditional 32-bit software implementations. In addition to providing advanced code density, the MIPS16e ASE also achieves a high level of power efficiency, and performance equivalent to that of 32-bit only implementations. The MIPS16e ASE also improves instruction cache hit rate. It is supported by hardware and software development tools from MIPS Technologies and other providers.
MIPS DSP ASE
The DSP ASE is an optional extension to the MIPS32/MIPS64 release 2 and newer instruction sets which can be used to accelerate a large range of "media" computations - particularly audio, since TV-resolution video. The DSP module comprises a set of instructions and state in the integer pipeline and requires minimal additional logic to implement in MIPS processor cores.
Unlike the bulk of the MIPS architecture, it's a fairly irregular set of operations, many chosen for a particular relevance to some key algorithm.
Its main novel features (vs original MIPS32):
- Saturating arithmetic (when a calculation overflows, deliver the representable number closest to the non-overflowed answer).
- Fixed-point arithmetic on signed 32- and 16-bit fixed-point fractions with a range of -1 to +1 (these are widely called "Q31" and "Q15").
- The existing MIPS32 instruction set includes integer multiplication and multiply-accumulate which delivers results into a double-size accumulator (called "hi/lo" and 64 bits on MIPS32 CPUs). The DSP ASE adds three more accumulators, and some different flavours of multiply-accumulate.
- SIMD instructions operating on 4 x unsigned bytes or 2 x 16-bit values packed into a 32-bit register (the 64-bit variant of the DSP ASE supports larger vectors, too).
- SIMD operations are basic arithmetic, shifts and some multiply-accumulate type operations.
To write DSP-ASE-enabled programs, you'll need to write assembler code or use the "intrinsics" (built-in pseudo-subroutines) which are more or less 1-to-1 with the underlying instructions.
Linux 2.6.12-rc5 starting 2005-05-31 adds support for the DSP ASE. Note that to actually make use of the DSP ASE a toolchain which support this is required. As of this writing only MIPS SDE has such support.
MIPS SIMD
Instruction set extensions designed to accelerate multimedia.
- 32 vector registers of 16 x 8-bit, 8 x 16-bit, 4 x 32-bit, and 2 x 64 bit vector elements
- Efficient vector parallel arithmetic operations on integer, fixed-point and floating-point data
- Operations on absolute value operands
- Rounding and saturation options available
- Full precision multiply and multiply-add
- Conversions between integer, floating-point, and fixed-point data
- Complete set of vector-level compare and branch instructions with no condition flag
- Vector (1D) and array (2D) shuffle operations
- Typed load and store instructions for endian-independent operation
- IEEE Standard for Floating-Point Arithmetic 754-2008 compliant
- Element precise floating-point exception signaling
- Pre-defined scalable extensions for chips with more gates/transistors
- Accelerates compute-intensive applications in conjunction with leveraging generic compiler support
- Software-programmable solution for consumer electronics applications or functions not covered by dedicated hardware
- Emerging data mining, feature extraction, image and video processing, and human-computer interaction applications
- High-performance scientific computing
eXtended Physical Address (XPA)
Provides extension to 40-bits of physical address bits (1 TB).
Enhanced Virtual Address (EVA)
Programmable kernel and user segment sizes.
MIPS Virtualization
Hardware supported virtualization technology.
MIPS Multi-Threading
Each multi-threaded MIPS core can support up to two VPEs (Virtual Processing Elements) which share a single pipeline as well as other hardware resources. However, since each VPE includes a complete copy of the processor state as seen by the software system, each VPE appears as a complete standalone processor to an SMP Linux operating system. For more fine-grained thread processing applications, each VPE is capable of supporting up to 9 TCs allocated across 2 VPEs. The TCs share a common execution unit but each has its own program counter and core register files so that each can handle a thread from the software. The MIPS MT architecture also allows the allocation of processor cycles to threads, and sets the relative thread priorities with an optional Quality of Service (QoS) manager block. This enables two prioritization mechanisms that determine the flow of information across the bus. The first mechanism allows the user to prioritize one thread over another. The second mechanism is used to allocate a specified ratio of the cycles to specific threads over time. The combined use of both mechanisms allows effective allocation of bandwidth to the set of threads, and better control of latencies. In real-time systems, system-level determinism is very critical, and the QoS block facilitates improvement of the predictability of a system. Hardware designers of advanced systems may replace the standard QoS block provided by MIPS Technologies with one that is specifically tuned for their application.
Single-threaded microprocessors today waste many cycles while waiting to access memory, considerably limiting system performance. The use of multi-threading masks the effect of memory latency by increasing processor utilization. As one thread stalls, additional threads are instantly fed into the pipeline and executed, resulting in a significant gain in application throughput. Users can allocate dedicated processing bandwidth to real-time tasks resulting in a guaranteed Quality of Service (QoS). MIPS’ MT technology constantly monitors the progress of threads and dynamically takes corrective actions to meet or exceed the real-time requirements. A processor pipeline can achieve 80-90% utilization by switching threads during data-dependent stalls or cache misses. All of this leads to an improved mobile device user experience, as responsiveness is greatly increased.
OmniShield
OmniShield™ enables next-generation SoC security.
SmartMIPS
Extends the MIPS32 Architectures with a set of security enhancements.
MDMX
MIPS-3D
MIPS16e
Contains 16-bit compressed code instructions. The core can execute both 16- and 32-bit instructions intermixed in the same program, and is compatible with both the MIPS32 and MIPS64 Architectures.
microMIPS
microMIPS32 and microMIPS64 are high performance code compression technologies that combine optimized 16- and 32-bit instructions in single, unified Instruction Set. As a complete ISA, microMIPS can operate standalone or in co-existence with the legacy-compatible MIPS32 instruction decoder, allowing programs to intermix 16- and 32-bit code without having to switch modes. microMIPS32 has 32x32b registers; 32 bits Virtual Address, up to 36 bits Physical Address (same as MIPS32). microMIPS64 has 32x64b registers; 64 bits Virtual Address, up to 59 bits Physical Address, adds 64- bit variables (same as MIPS64)
MIPS CorExtend UDI (User Defined Instructions)
Allows user to extend MIPS instruction set with user defined extensions which execute in parallel with the MIPS integer pipeline.
Microarchitectures based on the MIPS instruction set
.svg.png)
The first commercial MIPS model, the R2000, was announced in 1985. It added multiple-cycle multiply and divide instructions in a somewhat independent on-chip unit. New instructions were added to retrieve the results from this unit back to the register file; these result-retrieving instructions were interlocked.
The R2000 could be booted either big-endian or little-endian. It had thirty-one 32-bit general purpose registers, but no condition code register (the designers considered it a potential bottleneck), a feature it shares with the AMD 29000 and the Alpha. Unlike other registers, the program counter is not directly accessible.
The R2000 also had support for up to four co-processors, one of which was built into the main CPU and handled exceptions, traps and memory management, while the other three were left for other uses. One of these could be filled by the optional R2010 FPU, which had thirty-two 32-bit registers that could be used as sixteen 64-bit registers for double-precision.
MIPSel refers to a MIPS architecture using a little endian byte order. Since almost all MIPS microprocessors have the capability of operating with either little endian or big endian byte order, the term is used only for processors where little endian byte order has been pre-determined.
The R3000 succeeded the R2000 in 1988, adding 32 kB (soon increased to 64 kB) caches for instructions and data, along with cache coherency support for multiprocessor use. While there were flaws in the R3000s multiprocessor support, it still managed to be a part of several successful multiprocessor designs. The R3000 also included a built-in MMU, a common feature on CPUs of the era. The R3000, like the R2000, could be paired with a R3010 FPU. The R3000 was the first successful MIPS design in the marketplace, and eventually over one million were made. A speed-bumped version of the R3000 running up to 40 MHz, the R3000A delivered a performance of 32 VUPs (VAX Unit of Performance). The MIPS R3000A-compatible R3051 running at 33.8688 MHz was the processor used in the Sony PlayStation though it didn't have FPU or MMU. Third-party designs include Performance Semiconductor's R3400 and IDT's R3500, both of them were R3000As with an integrated R3010 FPU. Toshiba's R3900 was a virtually first SoC for the early handheld PCs that ran Windows CE. A radiation-hardened variant for space applications, the Mongoose-V, is a R3000 with an integrated R3010 FPU.
The R4000 series, released in 1991, extended the MIPS instruction set to a full 64-bit architecture, moved the FPU onto the main die to create a single-chip microprocessor, and operated at a radically high internal clock speed (it was introduced at 100 MHz). However, in order to achieve the clock speed the caches were reduced to 8 kB each and they took three cycles to access. The high operating frequencies were achieved through the technique of deep pipelining (called super-pipelining at the time). The improved R4400 followed in 1993. It had larger 16 kB primary caches, largely bug-free 64-bit operation, and support for a larger L2 cache.
MIPS, now a division of SGI called MTI, designed the low-cost R4200, the basis for the even cheaper R4300i. A derivative of this microprocessor, the NEC VR4300, was used in the Nintendo 64 game console.[14]


Quantum Effect Devices (QED), a separate company started by former MIPS employees, designed the R4600 Orion, the R4700 Orion, the R4650 and the R5000. Where the R4000 had pushed clock frequency and sacrificed cache capacity, the QED designs emphasized large caches which could be accessed in just two cycles and efficient use of silicon area. The R4600 and R4700 were used in low-cost versions of the SGI Indy workstation as well as the first MIPS based Cisco routers, such as the 36x0 and 7x00-series routers. The R4650 was used in the original WebTV set-top boxes (now Microsoft TV). The R5000 FPU had more flexible single precision floating-point scheduling than the R4000, and as a result, R5000-based SGI Indys had much better graphics performance than similarly clocked R4400 Indys with the same graphics hardware. SGI gave the old graphics board a new name when it was combined with R5000 in order to emphasize the improvement. QED later designed the RM7000 and RM9000 family of devices for embedded markets like networking and laser printers. QED was acquired by the semiconductor manufacturer PMC-Sierra in August 2000, the latter company continuing to invest in the MIPS architecture. The RM7000 included an on-board 256 kB level 2 cache and a controller for optional level three cache. The RM9xx0 were a family of SOC devices which included northbridge peripherals such as memory controller, PCI controller, gigabit ethernet controller and fast IO such as a hypertransport port.
The R8000 (1994) was the first superscalar MIPS design, able to execute two integer or floating point and two memory instructions per cycle. The design was spread over six chips: an integer unit (with 16 kB instruction and 16 kB data caches), a floating-point unit, three full-custom secondary cache tag RAMs (two for secondary cache accesses, one for bus snooping), and a cache controller ASIC. The design had two fully pipelined double precision multiply-add units, which could stream data from the 4 MB off-chip secondary cache. The R8000 powered SGI's POWER Challenge servers in the mid-1990s and later became available in the POWER Indigo2 workstation. Although its FPU performance fit scientific users quite well, its limited integer performance and high cost dampened appeal for most users, and the R8000 was in the marketplace for only a year and remains fairly rare.
In 1995, the R10000 was released. This processor was a single-chip design, ran at a faster clock speed than the R8000, and had larger 32 kB primary instruction and data caches. It was also superscalar, but its major innovation was out-of-order execution. Even with a single memory pipeline and simpler FPU, the vastly improved integer performance, lower price, and higher density made the R10000 preferable for most customers.
Some later designs have been based upon R10000 core. The R12000 used a 0.25 micrometre process to shrink the chip and achieve higher clock rates. The revised R14000 allowed higher clock rates with additional support for DDR SRAM in the off-chip cache. Later iterations are named the R16000 and the R16000A and feature increased clock speed and smaller die manufacturing compared with before.
Other members of the MIPS family include the R6000, an ECL implementation produced by Bipolar Integrated Technology. The R6000 introduced the MIPS II instruction set. Its TLB and cache architecture are different from all other members of the MIPS family. The R6000 did not deliver the promised performance benefits, and although it saw some use in Control Data machines, it quickly disappeared from the mainstream market. R5900 used in PS2 is a modified version of R5000 cpu with a customized instruction/data cache arrangement and Sony's propiertary 107 vector SIMD Multimedia Extensions(MMI). Its custom FPU isn't IEEE 754 compliant unlike FPUs used by R5000 and it also has COP2 VPU0.
Heterogeneous System Architecture
Imagination Technologies is a founding member of the HSA Foundation[15] and implementation of the technologies and standards elaborated by the consortium is to be expected. See Heterogeneous System Architecture.
History
RISC pioneer
In 1981, a team led by John L. Hennessy at Stanford University started work on what would become the first MIPS processor. The basic concept was to increase performance through the use of deep instruction pipelines. Pipelining as a basic technique was well known before (see IBM 801 for instance), but not developed into its full potential. CPUs are built up from a number of dedicated sub-units such as instruction decoders, ALUs (integer arithmetics and logic), load/store units (handling memory), and so on. In a traditional non-optimized design, a particular instruction in a program sequence must be (almost) completed before the next can be issued for execution; in a pipelined architecture, successive instructions can instead overlap in execution. For instance, at the same time as a mathematical instruction is fed into the floating point unit, the load/store unit can fetch the next instruction.
One major barrier to pipelining was that some instructions, like division, take longer to complete and the CPU therefore has to wait before passing the next instruction into the pipeline. One solution to this problem is to use a series of interlocks that allows stages to indicate that they are busy, pausing the other stages upstream. Hennessy's team viewed these interlocks as a major performance barrier since they had to communicate to all the modules in the CPU which takes time, and appeared to limit the clock speed. A major aspect of the MIPS design was to fit every sub-phase, including cache-access, of all instructions into one cycle, thereby removing any needs for interlocking, and permitting a single cycle throughput.
Although this design eliminated a number of useful instructions such as multiply and divide it was felt that the overall performance of the system would be dramatically improved because the chips could run at much higher clock rates. This ramping of the speed would be difficult with interlocking involved, as the time needed to set up locks is as much a function of die size as clock rate. The elimination of these instructions became a contentious point.
The other difference between the MIPS design and the competing Berkeley RISC involved the handling of subroutine calls. RISC used a technique called register windows to improve performance of these very common tasks. Each subroutine call required its own set of registers, which in turn required more real estate on the CPU and more complexity in its design. Hennessy felt that a careful compiler could find free registers without resorting to a hardware implementation, and that simply increasing the number of registers would not only make this simple, but increase the performance of all tasks.
In other ways the MIPS design was very much a typical RISC design. To save bits in the instruction word, RISC designs reduce the number of instructions to encode. The MIPS design uses 6 bits of the 32-bit word for the basic opcode;[16] the rest may contain a single 26-bit jump address or it may have up to four 5-bit fields specifying up to three registers plus a shift value combined with another 6-bits of opcode; another format, among several, specifies two registers combined with a 16-bit immediate value, etc. This allowed the CPU to load up the instruction and the data it needed in a single cycle, whereas an (older) non-RISC design, such as the MOS Technology 6502 for instance, required separate cycles to load the opcode and the data. This was one of the major performance improvements that RISC offered. However, modern non-RISC designs achieve this speed by other means (such as queues in the CPU).
First hardware
In 1984, Hennessy was convinced of the future commercial potential of the design, and left Stanford to form MIPS Computer Systems. They released their first design, the R2000, in 1985, improving the design as the R3000 in 1988. These 32-bit CPUs formed the basis of their company through the 1980s, used primarily in SGI's series of workstations and later Digital Equipment Corporation DECstation workstations and servers. The SGI commercial designs deviated from the Stanford academic research by implementing most of the interlocks in hardware, supplying full multiply and divide instructions (among others). The designs were guided, in part, by software architect Earl Killian who designed the MIPS III 64-bit instruction-set extension, and led the work on the R4000 microarchitecture.[17][18]
In 1991 MIPS released the first 64-bit microprocessor, the R4000. The R4000 has an advanced TLB where the entry contains not just virtual address but also the virtual address space id. This buffering eliminates the major performance problems from microkernels[19] that are slow on competing architectures (Pentium, PowerPC, Alpha) because of the need to flush the TLB on the frequent context switches. However, MIPS had financial difficulties while bringing it to market. The design was so important to SGI, at the time one of MIPS' few major customers, that SGI bought the company outright in 1992 in order to guarantee the design would not be lost. As a subsidiary of SGI, the company became known as MIPS Technologies.
Licensable architecture
In the early 1990s, MIPS started licensing their designs to third-party vendors. This proved fairly successful due to the simplicity of the core, which allowed it to be used in a number of applications that would have formerly used much less capable CISC designs of similar gate count and price—the two are strongly related; the price of a CPU is generally related to the number of gates and the number of external pins. Sun Microsystems attempted to enjoy similar success by licensing their SPARC core but was not nearly as successful. By the late 1990s MIPS was a powerhouse in the embedded processor field. According to MIPS Technologies Inc., there was an exponential growth, with 48-million MIPS-based CPU shipments and 49% of total RISC CPU market share in 1997.[20] MIPS was so successful that SGI spun off MIPS Technologies in 1998. Fully half of MIPS's income today comes from licensing their designs, while much of the rest comes from contract design work on cores that will then be produced by third parties.
In 1999 MIPS formalized their licensing system around two basic designs, the 32-bit MIPS32 (based on MIPS II with some additional features from MIPS III, MIPS IV, and MIPS V) and the 64-bit MIPS64 (based on MIPS V). NEC, Toshiba and SiByte (later acquired by Broadcom) each obtained licenses for the MIPS64 as soon as it was announced. Philips, LSI Logic and IDT have since joined them. Today, the MIPS cores are one of the most-used "heavyweight" cores in the marketplace for computer-like devices (hand-held computers, set-top boxes, etc.).
Since the MIPS architecture is licensable, it has attracted several processor start-up companies over the years. One of the first start-ups to design MIPS processors was Quantum Effect Devices (see next section). The MIPS design team that designed the R4300i started the company SandCraft, which designed the R5432 for NEC and later produced the SR71000, one of the first out-of-order execution processors for the embedded market. The original DEC StrongARM team eventually split into two MIPS-based start-ups: SiByte which produced the SB-1250, one of the first high-performance MIPS-based systems-on-a-chip (SOC); while Alchemy Semiconductor (later acquired by AMD) produced the Au-1000 SoC for low-power applications. Lexra used a MIPS-like architecture and added DSP extensions for the audio chip market and multithreading support for the networking market. Due to Lexra not licensing the architecture, two lawsuits were started between the two companies. The first was quickly resolved when Lexra promised not to advertise their processors as MIPS-compatible. The second (about MIPS patent 4814976 for handling unaligned memory access) was protracted, hurt both companies' business, and culminated in MIPS Technologies giving Lexra a free license and a large cash payment.
Two companies have emerged that specialize in building multi-core devices using the MIPS architecture. Raza Microelectronics, Inc. purchased the product line from failing SandCraft and later produced devices that contained eight cores that were targeted at the telecommunications and networking markets. Cavium, originally a security processor vendor also produced devices with eight CPU cores, and later up to 32 cores, for the same markets. Both of these companies designed their cores in-house, just licensing the architecture instead of purchasing cores from MIPS.
The desktop
Among the manufacturers which have made computer workstation systems using MIPS processors are SGI, MIPS Computer Systems, Inc., Whitechapel Workstations, Olivetti, Siemens-Nixdorf, Acer, Digital Equipment Corporation, NEC, and DeskStation.
Operating systems ported to the architecture include SGI's IRIX, Microsoft's Windows NT (through v4.0), Windows CE, Linux, FreeBSD, NetBSD, OpenBSD, UNIX System V, SINIX, QNX, and MIPS Computer Systems' own RISC/os.
There was speculation in the early 1990s that MIPS and other powerful RISC processors would overtake the Intel IA-32 architecture. This was encouraged by the support of the first two versions of Microsoft's Windows NT for Alpha, MIPS and PowerPC—and to a lesser extent the Clipper architecture and SPARC. However, as Intel quickly released faster versions of their Pentium class CPUs, Microsoft Windows NT v4.0 dropped support for anything but IA-32 and Alpha. With SGI's decision to transition to the Itanium and IA-32 architectures in 2007 (following a 2006 Chapter 11 bankruptcy[21]) and 2009 acquisition by Rackable Systems, Inc., support ended for the MIPS/IRIX consumer market in December, 2013 as originally scheduled. However, a support team still exists for special circumstances and refurbished systems that are still available on a limited basis.[22]
Embedded markets

Through the 1990s, the MIPS architecture was widely adopted by the embedded market, including for use in computer networking, telecommunications, video arcade games, video game consoles, computer printers, digital set-top boxes, digital televisions, DSL and cable modems, and personal digital assistants.
The low power-consumption and heat characteristics of embedded MIPS implementations, the wide availability of embedded development tools, and knowledge about the architecture means use of MIPS microprocessors in embedded roles is likely to remain common.
Synthesizeable cores for embedded markets
In recent years most of the technology used in the various MIPS generations has been offered as IP-cores (building-blocks) for embedded processor designs. Both 32-bit and 64-bit basic cores are offered, known as the 4K and 5K. These cores can be mixed with add-in units such as FPUs, SIMD systems, various input/output devices, etc.
MIPS cores have been commercially successful, now being used in many consumer and industrial applications. MIPS cores can be found in newer Cisco, Linksys and Mikrotik's routerboard routers, cable modems and ADSL modems, smartcards, laser printer engines, set-top boxes, robots, handheld computers, Nintendo 64, Sony PlayStation 2 and Sony PlayStation Portable. In cellphone/PDA applications, MIPS has been largely unable to displace the incumbent, competing ARM architecture.
MIPS architecture processors include: IDT RC32438; ATI/AMD Xilleon; Alchemy Au1000, 1100, 1200; Broadcom Sentry5; RMI XLR7xx, Cavium Octeon CN30xx, CN31xx, CN36xx, CN38xx and CN5xxx; Infineon Technologies EasyPort, Amazon, Danube, ADM5120, WildPass, INCA-IP, INCA-IP2; Microchip Technology PIC32; NEC EMMA and EMMA2, NEC VR4181A, VR4121, VR4122, VR4181A, VR4300, VR5432, VR5500; Oak Technologies Generation; PMC-Sierra RM11200; QuickLogic QuickMIPS ESP; Toshiba Donau, Toshiba TMPR492x, TX4925, TX9956, TX7901; KOMDIV-32, KOMDIV-64, ELVEES Multicore from Russia.
MIPS-based supercomputers
One of the more interesting applications of the MIPS architecture is its use in massive processor count supercomputers. Silicon Graphics (SGI) refocused its business from desktop graphics workstations to the high-performance computing market in the early 1990s. The success of the company's first foray into server systems, the Challenge series based on the R4400 and R8000, and later R10000, motivated SGI to create a vastly more powerful system. The introduction of the integrated R10000 allowed SGI to produce a system, the Origin 2000, eventually scalable to 1024 CPUs using its NUMAlink cc-NUMA interconnect. The Origin 2000 begat the Origin 3000 series which topped out with the same 1024 maximum CPU count but using the R14000 and R16000 chips up to 700 MHz. Its MIPS based supercomputers were withdrawn in 2005 when SGI made the strategic decision to move to Intel's IA-64 architecture.
A high-performance computing startup called SiCortex introduced a massively parallel MIPS based supercomputer in 2007. The machines are based on the MIPS64 architecture and a high performance interconnect using a Kautz graph topology. The system is very power efficient and computationally powerful. The most innovative aspect of the system was its multicore processing node which integrates six MIPS64 cores, a crossbar switch memory controller, interconnect DMA engine, Gigabit Ethernet and PCI Express controllers all on a single chip which consumes only 10 watts of power, yet has a peak floating point performance of 6 gigaFLOPS. The most powerful configuration, the SC5832, is a single cabinet supercomputer consisting of 972 such node chips for a total of 5832 MIPS64 processor cores and 8.2 teraFLOPS of peak performance.
Loongson
Loongson is a MIPS-compatible family of microprocessors designed by the Chinese Academy of Sciences. The internal microarchitecture of Loongson microprocessors was designed independently by the Chinese, and early implementations of the family lacked four instructions patented by MIPS Technologies.[23] In June 2009, ICT licensed the MIPS32 and MIPS64 architectures directly from MIPS Technologies.[24]
Starting in 2006, a number of companies released Loongson-based computers, including nettops and netbooks designed for low-power use.[25][26]
Dawning 6000
The high-performance Dawning 6000, which has a projected speed of over one quadrillion operations per second, will incorporate the Loongson processor as its core. Dawning 6000 is currently jointly developed by the Institute of Computing Technology under the Chinese Academy of Sciences and the Dawning Information Industry Company. Li Guojie, chairman of Dawning Information Industry Company and director and academician of the Institute of Computing Technology, said research and development of the Dawning 6000 is expected to be completed in two years. By then, Chinese-made high-performance computers will be expected to achieve two major breakthroughs: first, the adoption of domestic-made central processing units (CPUs); second, the existing cluster-based system structure of high-performance computers will be changed once the computing speed reaches one quadrillion operations per second.
MIPS Aptiv
Announced in 2012,[27] the MIPS Aptiv family includes three 32-bit CPU products based on the MIPS32 Release 3 architecture.
microAptiv
microAptiv[28] is a compact, real-time embedded processor core with a five-stage pipeline and the microMIPS code compression instruction set architecture. microAptiv can be either configured as a microprocessor (microAptiv UP) with instruction and data caches and a Memory Management Unit or as a microcontroller (microAptiv UC) with a Memory Protection Unit. The CPU integrates DSP and SIMD functionality to address signal processing requirements for entry-level embedded segments including industrial control, smart meters, automotive and wired/wireless communications.
interAptiv
interAptiv[29] is a multiprocessor core leveraging a nine-stage pipeline with multi-threading. The core can be used for highly-parallel applications requiring cost and power optimization, such as smart gateways, baseband processing in LTE user equipment and small cells, SSD controllers and automotive equipment.
proAptiv
proAptiv[30] is a superscalar, out-of-order processor core that is available in single and multi-core product versions. proAptiv is designed for applications processing in connected consumer electronics and control plane processing in networking applications.
MIPS Warrior
Announced in June 2013,[31] the MIPS Warrior family includes multiple 32-bit and 64-bit CPU products based on the MIPS Release 5 and 6 architectures.
Warrior M-class
32-bit MIPS cores for embedded and microcontroller applications:
- MIPS M5100 and MIPS M5150 cores (MIPS32 Release 5):[32] five-stage pipeline architecture, microMIPS ISA, the MIPS DSP Module r2, fast interrupt handling, advanced debug/profiling capabilities and power management.
- MIPS M6200 and M6250 cores (MIPS32 Release 6):[33] six-stage pipeline architecture, microMIPS ISA, dedicated DSP and SIMD module
Warrior I-class
64-bit MIPS CPUs for high-performance, low-power embedded applications:
- MIPS I6400 multiprocessor core (MIPS64 Release 6):[34] simultaneous multi-threading (SMT), hardware virtualization, 128-bit SIMD, advanced power management, multi-context security, extensible to coherent multi-cluster operation.
Warrior P-class
32-bit and 64-bit MIPS application processors:
- MIPS P5600 multiprocessor core (MIPS32 Release 5):[35] hardware virtualization with hardware table walk, 128-bit SIMD, 40-bit eXtended Physical Addressing (XPA)
- MIPS P6600 multiprocessor core (MIPS64 Release 6): hardware virtualization with hardware table walk, 128-bit SIMD
MIPS instruction formats
Instructions are divided into three types: R, I and J. Every instruction starts with a 6-bit opcode. In addition to the opcode, R-type instructions specify three registers, a shift amount field, and a function field; I-type instructions specify two registers and a 16-bit immediate value; J-type instructions follow the opcode with a 26-bit jump target.[36][37]
The following are the three formats used for the core instruction set:
| Type | -31- format (bits) -0- | |||||
|---|---|---|---|---|---|---|
| R | opcode (6) | rs (5) | rt (5) | rd (5) | shamt (5) | funct (6) |
| I | opcode (6) | rs (5) | rt (5) | immediate (16) | ||
| J | opcode (6) | address (26) | ||||
MIPS assembly language
These are assembly language instructions that have direct hardware implementation, as opposed to pseudoinstructions which are translated into multiple real instructions before being assembled.
- In the following, the register letters d, t, and s are placeholders for (register) numbers or register names.
- C denotes a constant (immediate).
- All the following instructions are native instructions.
- Opcodes and funct codes are in hexadecimal.
- The MIPS32 Instruction Set states that the word unsigned as part of Add and Subtract instructions, is a misnomer. The difference between signed and unsigned versions of commands is not a sign extension (or lack thereof) of the operands, but controls whether a trap is executed on overflow (e.g. Add) or an overflow is ignored (Add unsigned). An immediate operand CONST to these instructions is always sign-extended.
Integer
MIPS has 32 integer registers. Data must be in registers to perform arithmetic. Register $0 always holds 0 and register $1 is normally reserved for the assembler (for handling pseudo instructions and large constants).
The encoding shows which bits correspond to which parts of the instruction. A hyphen (-) is used to indicate don't cares.
| Category | Name | Instruction syntax | Meaning | Format/opcode/funct | Notes/Encoding | ||
|---|---|---|---|---|---|---|---|
| Add | add $d,$s,$t | $d = $s + $t | R | 0 | 2016 | adds two registers, executes a trap on overflow000000ss sssttttt ddddd--- --100000 | |
| Add unsigned | addu $d,$s,$t | $d = $s + $t | R | 0 | 2116 | as above but ignores an overflow000000ss sssttttt ddddd--- --100001 | |
| Subtract | sub $d,$s,$t | $d = $s - $t | R | 0 | 2216 | subtracts two registers, executes a trap on overflow000000ss sssttttt ddddd--- --100010 | |
| Subtract unsigned | subu $d,$s,$t | $d = $s - $t | R | 0 | 2316 | as above but ignores an overflow000000ss sssttttt ddddd000 00100011 | |
| Add immediate | addi $t,$s,C | $t = $s + C (signed) | I | 816 | - | Used to add sign-extended constants (and also to copy one register to another: addi $1, $2, 0), executes a trap on overflow001000ss sssttttt CCCCCCCC CCCCCCCC | |
| Add immediate unsigned | addiu $t,$s,C | $t = $s + C (signed) | I | 916 | - | as above but ignores an overflow001001ss sssttttt CCCCCCCC CCCCCCCC | |
| Multiply | mult $s,$t | LO = (($s * $t) << 32) >> 32; HI = ($s * $t) >> 32; | R | 0 | 1816 | Multiplies two registers and puts the 64-bit result in two special memory spots - LO and HI. Alternatively, one could say the result of this operation is: (int HI,int LO) = (64-bit) $s * $t. See mfhi and mflo for accessing LO and HI regs. | |
| Multiply unsigned | multu $s,$t | LO = (($s * $t) << 32) >> 32; HI = ($s * $t) >> 32; | R | 0 | 1916 | Multiplies two registers and puts the 64-bit result in two special memory spots - LO and HI. Alternatively, one could say the result of this operation is: (int HI,int LO) = (64-bit) $s * $t. See mfhi and mflo for accessing LO and HI regs. | |
| Divide | div $s, $t | LO = $s / $t HI = $s % $t | R | 0 | 1A16 | Divides two registers and puts the 32-bit integer result in LO and the remainder in HI.[36] | |
| Divide unsigned | divu $s, $t | LO = $s / $t HI = $s % $t | R | 0 | 1B16 | Divides two registers and puts the 32-bit integer result in LO and the remainder in HI. | |
| Load word | lw $t,C($s) | $t = Memory[$s + C] | I | 2316 | - | loads the word stored from: MEM[$s+C] and the following 3 bytes. | |
| Load halfword | lh $t,C($s) | $t = Memory[$s + C] (signed) | I | 2116 | - | loads the halfword stored from: MEM[$s+C] and the following byte. Sign is extended to width of register. | |
| Load halfword unsigned | lhu $t,C($s) | $t = Memory[$s + C] (unsigned) | I | 2516 | - | As above without sign extension. | |
| Load byte | lb $t,C($s) | $t = Memory[$s + C] (signed) | I | 2016 | - | loads the byte stored from: MEM[$s+C]. | |
| Load byte unsigned | lbu $t,C($s) | $t = Memory[$s + C] (unsigned) | I | 2416 | - | As above without sign extension. | |
| Store word | sw $t,C($s) | Memory[$s + C] = $t | I | 2B16 | - | stores a word into: MEM[$s+C] and the following 3 bytes. The order of the operands is a large source of confusion. | |
| Store half | sh $t,C($s) | Memory[$s + C] = $t | I | 2916 | - | stores the least-significant 16-bit of a register (a halfword) into: MEM[$s+C]. | |
| Store byte | sb $t,C($s) | Memory[$s + C] = $t | I | 2816 | - | stores the least-significant 8-bit of a register (a byte) into: MEM[$s+C]. | |
| Load upper immediate | lui $t,C | $t = C << 16 | I | F16 | - | loads a 16-bit immediate operand into the upper 16-bits of the register specified. Maximum value of constant is 216-1 | |
| Move from high | mfhi $d | $d = HI | R | 0 | 1016 | Moves a value from HI to a register. Do not use a multiply or a divide instruction within two instructions of mfhi (that action is undefined because of the MIPS pipeline). | |
| Move from low | mflo $d | $d = LO | R | 0 | 1216 | Moves a value from LO to a register. Do not use a multiply or a divide instruction within two instructions of mflo (that action is undefined because of the MIPS pipeline). | |
| Move from Control Register | mfcZ $t, $d | $t = Coprocessor[Z].ControlRegister[$d] | R | 0 | Moves a 4 byte value from Coprocessor Z Control register to a general purpose register. Sign extension. | ||
| Move to Control Register | mtcZ $t, $d | Coprocessor[Z].ControlRegister[$d] = $t | R | 0 | Moves a 4 byte value from a general purpose register to a Coprocessor Z Control register. Sign extension. | ||
| And | and $d,$s,$t | $d = $s & $t | R | 0 | 2416 | Bitwise and000000ss sssttttt ddddd--- --100100 | |
| And immediate | andi $t,$s,C | $t = $s & C | I | C16 | - | Leftmost 16 bits are padded with 0s001100ss sssttttt CCCCCCCC CCCCCCCC | |
| Or | or $d,$s,$t | $d = $s | $t | R | 0 | 2516 | Bitwise or | |
| Or immediate | ori $t,$s,C | $t = $s | C | I | D16 | - | Leftmost 16 bits are padded with 0s | |
| Exclusive or | xor $d,$s,$t | $d = $s ^ $t | R | 0 | 2616 | Bitwise exclusive or | |
| Exclusive or immediate | xori $t,$s,C | $t = $s ^ C | I | E16 | - | Leftmost 16 bits are padded with 0s | |
| Nor | nor $d,$s,$t | $d = ~ ($s | $t) | R | 0 | 2716 | Bitwise nor | |
| Set on less than | slt $d,$s,$t | $d = ($s < $t) | R | 0 | 2A16 | Tests if one register is less than another. | |
| Set on less than unsigned | sltu $d,$s,$t | $d = ($s < $t) | R | 0 | 2B16 | Tests if unsigned integer in one register is less than another. | |
| Set on less than immediate | slti $t,$s,C | $t = ($s < C) | I | A16 | - | Tests if one register is less than a constant. | |
| Shift left logical immediate | sll $d,$t,shamt | $d = $t << shamt | R | 0 | 0 | shifts shamt number of bits to the left (multiplies by ) | |
| Shift right logical immediate | srl $d,$t,shamt | $d = $t >> shamt | R | 0 | 216 | shifts shamt number of bits to the right - zeros are shifted in (divides by ). Note that this instruction only works as division of a two's complement number if the value is positive. | |
| Shift right arithmetic immediate | sra $d,$t,shamt | R | 0 | 316 | shifts shamt number of bits - the sign bit is shifted in (divides a positive or even 2's complement number by ) | ||
| Shift left logical | sllv $d,$t,$s | $d = $t << $s | R | 0 | 4 16 | shifts $s number of bits to the left (multiplies by ) | |
| Shift right logical | srlv $d,$t,$s | $d = $t >> $s | R | 0 | 616 | shifts $s number of bits to the right - zeros are shifted in (divides by ). Note that this instruction only works as division of a two's complement number if the value is positive. | |
| Shift right arithmetic | srav $d,$t,$s | R | 0 | 716 | shifts $s number of bits - the sign bit is shifted in (divides a positive or even 2's complement number by ) | ||
| Branch on equal | beq $s,$t,C | if ($s == $t) go to PC+4+4*C | I | 416 | - | Goes to the instruction at the specified address if two registers are equal.000100ss sssttttt CCCCCCCC CCCCCCCC | |
| Branch on not equal | bne $s,$t,C | if ($s != $t) go to PC+4+4*C | I | 516 | - | Goes to the instruction at the specified address if two registers are not equal. | |
| Jump | j C | PC = PC+4[31:28] . C*4 | J | 216 | - | Unconditionally jumps to the instruction at the specified address. | |
| Jump register | jr $s | goto address $s | R | 0 | 816 | Jumps to the address contained in the specified register | |
| Jump and link | jal C | $31 = PC + 4; PC = PC+4[31:28] . C*4 | J | 316 | - | For procedure call - used to call a subroutine, $31 holds the return address; returning from a subroutine is done by: jr $31. Return address is PC + 8, not PC + 4 due to the use of a branch delay slot which forces the instruction after the jump to be executed | |




Note: In MIPS assembly code, the offset for branching instructions can be represented by a label elsewhere in the code.
Note: There is no corresponding load lower immediate instruction; this can be done ori (or immediate) with the register $0 (whose value is always zero). For example, both addi $1, $0, 100 and ori $1, $0, 100 load the decimal value 100 into register $1. However, if you are trying to create a 32-bit value with lui (load upper immediate) followed by a "load lower immediate", it is wise to use ori $1, $0, 100. The instruction addi will sign extend the most significant bit and potentially overwrite the upper 16 bits when adding negative values.
Note: Subtracting an immediate can be done with adding the negation of that value as the immediate.
Floating point
MIPS has 32 floating-point registers. Two registers are paired for double precision numbers. Odd numbered registers cannot be used for arithmetic or branching, just as part of a double precision register pair.
| Category | Name | Instruction syntax | Meaning | Format | opcode | funct | Notes/Encoding |
|---|---|---|---|---|---|---|---|
| FP add single | add.s $x,$y,$z | $x = $y + $z | Floating-Point add (single precision) | ||||
| FP subtract single | sub.s $x,$y,$z | $x = $y - $z | Floating-Point subtract (single precision) | ||||
| FP multiply single | mul.s $x,$y,$z | $x = $y * $z | Floating-Point multiply (single precision) | ||||
| FP divide single | div.s $x,$y,$z | $x = $y / $z | Floating-Point divide (single precision) | ||||
| FP add double | add.d $x,$y,$z | $x = $y + $z | Floating-Point add (double precision) | ||||
| FP subtract double | sub.d $x,$y,$z | $x = $y - $z | Floating-Point subtract (double precision) | ||||
| FP multiply double | mul.d $x,$y,$z | $x = $y * $z | Floating-Point multiply (double precision) | ||||
| FP divide double | div.d $x,$y,$z | $x = $y / $z | Floating-Point divide (double precision) | ||||
| Load word coprocessor | lwcZ $x,CONST ($y) | Coprocessor[Z].DataRegister[$x] = Memory[$y + CONST] | I | Loads the 4 byte word stored from: MEM[$y+CONST] into a Coprocessor data register. Sign extension. | |||
| Store word coprocessor | swcZ $x,CONST ($y) | Memory[$y + CONST] = Coprocessor[Z].DataRegister[$x] | I | Stores the 4 byte word held by a Coprocessor data register into: MEM[$y+CONST]. Sign extension. | |||
| FP compare single (eq,ne,lt,le,gt,ge) | c.lt.s $f2,$f4 | cond = ($f2 < $f4) | Floating-point compare less than single precision | ||||
| FP compare double (eq,ne,lt,le,gt,ge) | c.lt.d $f2,$f4 | cond = ($f2 < $f4) | Floating-point compare less than double precision | ||||
| branch on FP true | bc1t 100 | if (cond)
goto PC+4+100;
| PC relative branch if FP condition | ||||
| branch on FP false | bc1f 100 | if (cond)
goto PC+4+100;
| PC relative branch if not condition |
Pseudo instructions
These instructions are accepted by the MIPS assembler, although they are not real instructions within the MIPS instruction set. Instead, the assembler translates them into sequences of real instructions.
| Name | instruction syntax | Real instruction translation | meaning |
|---|---|---|---|
| Move | move $rt,$rs | add $rt,$rs,$zero | R[rt]=R[rs] |
| Clear | clear $rt | add $rt,$zero,$zero | R[rt]=0 |
| Not | not $rt, $rs | nor $rt, $rs, $zero | R[rt]=~R[rs] |
| Load Address | la $rd, LabelAddr | lui $rd, LabelAddr[31:16] ori $rd,$rd, LabelAddr[15:0] | $rd = Label Address |
| Load Immediate | li $rd, IMMED[31:0] | lui $rd, IMMED[31:16] ori $rd,$rd, IMMED[15:0] | $rd = 32 bit Immediate value |
| Branch unconditionally | b Label | beq $zero,$zero,Label | PC=Label |
| Branch and link | bal Label | bgezal $zero,Label | R[31]=PC+8;
PC=Label;
|
| Branch if greater than | bgt $rs,$rt,Label | slt $at,$rt,$rs bne $at,$zero,Label | if (R[rs]>R[rt])
PC=Label
|
| Branch if less than | blt $rs,$rt,Label | slt $at,$rs,$rt bne $at,$zero,Label | if (R[rs]<R[rt])
PC=Label
|
| Branch if greater than or equal | bge $rs,$rt,Label | slt $at,$rs,$rt beq $at,$zero,Label | if (R[rs]>=R[rt])
PC=Label
|
| Branch if less than or equal | ble $rs,$rt,Label | slt $at,$rt,$rs beq $at,$zero,Label | if (R[rs]<=R[rt])
PC=Label
|
| Branch if less than or equal to zero | blez $rs,Label | slt $at,$zero,$rs beq $at,$zero,Label | if (R[rs]<=0)
PC=Label
|
| Branch if greater than unsigned | bgtu $rs,$rt,Label | sltu $at,$rt,$rs bne $at,$zero,Label | if (R[rs]>R[rt])
PC=Label
|
| Branch if greater than zero | bgtz $rs,Label | slt $at,$zero,$rs bne $at,$zero,Label | if (R[rs]>0)
PC=Label
|
| Branch if equal to zero | beqz $rs,Label | beq $rs,$zero,Label | if (R[rs]==0)
PC=Label
|
| Branch if not equal to zero | bnez $rs,Label | bne $rs,$zero,Label | if (R[rs]!=0)
PC=Label
|
| Multiplies and returns only first 32 bits | mul $d, $s, $t | mult $s, $t mflo $d | $d = $s * $t |
| Divides and returns quotient | div $d, $s, $t | div $s, $t mflo $d | $d = $s / $t |
| Divides and returns remainder | rem $d, $s, $t | div $s, $t mfhi $d | $d = $s % $t |
Other instructions
- NOP (no operation) (machine code 0x00000000, interpreted by CPU as
sll $0,$0,0) - break (breaks the program, used by debuggers)
- syscall (used for system calls to the operating system)
Many other pseudoinstructions and floating-point instructions present in MIPS R2000 are given in Appendix B.10 of Computer Organization and Design, Fourth Edition by Patterson and Hennessy.
Example code
The following sample code implements the Euler's totient function in MIPS assembly language:
.text
.globl main
main:
la $a0, query #First the query
li $v0, 4
syscall
li $v0, 5 #Read the input
syscall
move $t0, $v0 #store the value in a temporary variable
#store the base values in $t1, $t2
# $t1 iterates from m-1 to 1
# $t2 maintains a counter of the number of coprimes less than m
sub $t1, $t0, 1
li $t2, 0
tot:
blez $t1, done #termination condition
move $a0, $t0 #Argument passing
move $a1, $t1 #Argument passing
jal gcd #to GCD function
sub $t3, $v0, 1
beqz $t3, inc #checking if gcd is one
addi $t1, $t1, -1 #decrementing the iterator
b tot
inc:
addi $t2, $t2, 1 #incrementing the counter
addi $t1, $t1, -1 #decrementing the iterator
b tot
gcd: #recursive definition
addi $sp, $sp, -12
sw $a1, 8($sp)
sw $a0, 4($sp)
sw $ra, 0($sp)
move $v0, $a0
beqz $a1, gcd_return #termination condition
move $t4, $a0 #computing GCD
move $a0, $a1
remu $a1, $t4, $a1
jal gcd
lw $a1, 8($sp)
lw $a0, 4($sp)
gcd_return:
lw $ra, 0($sp)
addi $sp, $sp, 12
jr $ra
done: #print the result
#first the message
la $a0, result_msg
li $v0, 4
syscall
#then the value
move $a0, $t2
li $v0, 1
syscall
#exit
li $v0, 10
syscall
.data
query: .asciiz "Input m = "
result_msg: .asciiz "Totient(m) = "
Compiler register usage
The hardware architecture specifies that:
- General purpose register $0 always returns a value of 0.
- General purpose register $31 is used as the link register for jump and link instructions.
- HI and LO are used to access the multiplier/divider results, accessed by the mfhi (move from high) and mflo commands.
These are the only hardware restrictions on the usage of the general purpose registers.
The various MIPS tool-chains implement specific calling conventions that further restrict how the registers are used. These calling conventions are totally maintained by the tool-chain software and are not required by the hardware.
| Name | Number | Use | Callee must preserve? |
|---|---|---|---|
| $zero | $0 | constant 0 | N/A |
| $at | $1 | assembler temporary | No |
| $v0–$v1 | $2–$3 | values for function returns and expression evaluation | No |
| $a0–$a3 | $4–$7 | function arguments | No |
| $t0–$t7 | $8–$15 | temporaries | No |
| $s0–$s7 | $16–$23 | saved temporaries | Yes |
| $t8–$t9 | $24–$25 | temporaries | No |
| $k0–$k1 | $26–$27 | reserved for OS kernel | N/A |
| $gp | $28 | global pointer | Yes (except PIC code) |
| $sp | $29 | stack pointer | Yes |
| $fp | $30 | frame pointer | Yes |
| $ra | $31 | return address | N/A |
| Name | Number | Use | Callee must preserve? |
|---|---|---|---|
| $zero | $0 | constant 0 | N/A |
| $at | $1 | assembler temporary | No |
| $v0–$v1 | $2–$3 | values for function returns and expression evaluation | No |
| $a0–$a7 | $4–$11 | function arguments | No |
| $t4–$t7 | $12–$15 | temporaries | No |
| $s0–$s7 | $16–$23 | saved temporaries | Yes |
| $t8–$t9 | $24–$25 | temporaries | No |
| $k0–$k1 | $26–$27 | reserved for OS kernel | N/A |
| $gp | $28 | global pointer | Yes |
| $sp | $29 | stack pointer | Yes |
| $s8 | $30 | frame pointer | Yes |
| $ra | $31 | return address | N/A |
Registers that are preserved across a call are registers that (by convention) will not be changed by a system call or procedure (function) call. For example, $s-registers must be saved to the stack by a procedure that needs to use them, and $sp and $fp are always incremented by constants, and decremented back after the procedure is done with them (and the memory they point to). By contrast, $ra is changed automatically by any normal function call (ones that use jal), and $t-registers must be saved by the program before any procedure call (if the program needs the values inside them after the call).
Simulators
Open Virtual Platforms (OVP)[39] includes the freely available for non-commercial use simulator OVPsim, a library of models of processors, peripherals and platforms, and APIs which enable users to develop their own models. The models in the library are open source, written in C, and include the MIPS 4K, 24K, 34K, 74K, 1004K, 1074K, M14K, microAptiv, interAptiv, proAptiv 32 bit cores and the MIPS 64bit 5K range of cores. These models are created and maintained by Imperas[40] and in partnership with MIPS Technologies have been tested and assigned the MIPS-Verified (tm) mark. Sample MIPS-based platforms include both bare metal environments and platforms for booting unmodified Linux binary images. These platforms–emulators are available as source or binaries and are fast, free for non-commercial usage, and are easy to use. OVPsim is developed and maintained by Imperas and is very fast (hundreds of million of instructions per second), and built to handle multicore homogeneous and heterogeneous architectures and systems.
There is a freely available MIPS32 simulator (earlier versions simulated only the R2000/R3000) called SPIM for use in education. EduMIPS64[41] is a GPL graphical cross-platform MIPS64 CPU simulator, written in Java/Swing. It supports a wide subset of the MIPS64 ISA and allows the user to graphically see what happens in the pipeline when an assembly program is run by the CPU. It has educational purposes and is used in some computer architecture courses in universities around the world.
MARS[42] is another GUI-based MIPS emulator designed for use in education, specifically for use with Hennessy's Computer Organization and Design.
WebMIPS[43] is a browser based MIPS simulator with visual representation of a generic, pipelined processor. This simulator is quite useful for register tracking during step by step execution.
More advanced free emulators are available from the GXemul (formerly known as the mips64emul project) and QEMU projects. These emulate the various MIPS III and IV microprocessors in addition to entire computer systems which use them.
Commercial simulators are available especially for the embedded use of MIPS processors, for example Wind River Simics (MIPS 4Kc and 5Kc, PMC RM9000, QED RM7000, Broadcom/Netlogic ec4400, Cavium Octeon I), Imperas (all MIPS32 and MIPS64 cores), VaST Systems (R3000, R4000), and CoWare (the MIPS4KE, MIPS24K, MIPS25Kf and MIPS34K).
See also
- DLX, a very similar architecture designed by John L. Hennessy (creator of MIPS) for teaching purposes
- MIPS-X, developed as a follow-on project to the MIPS architecture
References
- ↑ "MIPS32 Architecture". Imagination Technologies. Retrieved 4 Jan 2014.
- ↑ "MIPS64 Architecture". Imagination Technologies. Retrieved 4 Jan 2014.
- ↑ "MIPS-3D ASE". Imagination Technologies. Retrieved 4 Jan 2014.
- ↑ "MIPS16e". Imagination Technologies. Retrieved 4 Jan 2014.
- ↑ "MIPS Multithreading". Imagination Technologies. Retrieved 4 Jan 2014.
- ↑ University of California, Davis. "ECS 142 (Compilers) References & Tools page". Retrieved 28 May 2009.
- ↑ Rubio, Victor P. "A FPGA Implementation of a MIPS RISC Processor for Computer Architecture Education" (PDF). New Mexico State University. Retrieved 22 December 2011.
- ↑ "Silicon Graphics Introduces Enhanced MIPS Architecture to Lead the Interactive Digital Revolution". Silicon Graphics, Inc. 21 October 1996.
- 1 2 Gwennap, Linley (18 November 1996). "Digital, MIPS Add Multimedia Extensions". Microprocessor Report. pp. 24–28.
- 1 2 3 4 5 "MIPS Technologies, Inc. Enhances Architecture to Support Growing Need for IP Re-Use and Integration" (Press release). Business Wire. May 3, 1999.
- ↑ "MIPS skips Release 4 amid bidding war". EE Times. 10 December 2012.
- ↑ "Latest Release of MIPS Architecture Includes Virtualization and SIMD Key Functionality for Enabling Next Generation of MIPS-Based Products" (Press release). MIPS Technologies. December 6, 2012. Archived from the original on 13 December 2012.
- ↑ https://imgtec.com/mips/architectures/mips32/
- ↑ NEC Offers Two High Cost Performance 64-bit RISC Microprocessors
- ↑ "HSA Foundation homepage".
- ↑ Morgan Kaufmann Publishers, Computer Organization and Design, David A. Patterson & John L. Hennessy, Edition 3, ISBN 1-55860-604-1, page 63
- ↑ "Earl Killian". Paravirtual. 26 November 2010. Retrieved 26 November 2010.
- ↑ "S-1 Supercomputer Alumni: Earl Killian". Clemson University. 28 June 2005. Retrieved 26 November 2010.
Earl Killian's early work w... As MIPS's Director of Architecture, he designed the MIPS III 64-bit instruction-set extension, and led the work on the R4000 microarchitecture. He was a cofounder of QED, which created the R4600 and R5000 MIPS processors. Most recently he was chief architect at Tensilica working on configurable/extensible processors.
- ↑ Jochen Liedtke(1995). On micro kernel construction. 15th Symposium on Operating Systems Principles, Copper Mountain Resort, Colorado.
- ↑ "MIPS Brochure" (PDF). MIPS Technologies Inc. Retrieved March 2, 2013.
- ↑ Patrick Fitzgerald (6 May 2006). "Silicon Graphics Seeks Chapter 11 As Sales Decline". Wall Street Journal. (subscription required (help)).
- ↑ "End of General Availability for MIPS® IRIX® Products". 2013.
- ↑ China's Microprocessor Dilemma
- ↑ China’s Institute of Computing Technology Licenses Industry-Standard MIPS Architectures
- ↑ "LinuxDevices article about the Municator". Archived from the original on 2012-12-16.
- ↑ "Yeelong Specs". LinuxDevices. 22 October 2008. Archived from the original on 2012-12-10.
- ↑ S, Ganesh T. "MIPS Technologies Updates Processor IP Lineup with Aptiv Series". www.anandtech.com. Retrieved 2016-06-22.
- ↑ "microAptiv Processor Core - Imagination Technologies". Imagination Technologies. Retrieved 2016-06-22.
- ↑ "interAptiv Processor Core - Imagination Technologies". Imagination Technologies. Retrieved 2016-06-22.
- ↑ "proAptiv Processor Core - Imagination Technologies". Imagination Technologies. Retrieved 2016-06-22.
- ↑ "Introducing the MIPS Series5 'Warrior' CPU cores: the next revolution in processor IP from Imagination - Imagination Technologies". Imagination Technologies. 2013-06-26. Retrieved 2016-06-22.
- ↑ "M-Class M51xx Core Family - Imagination Technologies". Imagination Technologies. Retrieved 2016-06-22.
- ↑ "M-Class M6200 and M6250 Processor Cores - Imagination Technologies". Imagination Technologies. Retrieved 2016-06-22.
- ↑ "I-Class I6400 Multiprocessor Core - Imagination Technologies". Imagination Technologies. Retrieved 2016-06-22.
- ↑ "P-Class P5600 Multiprocessor Core - Imagination Technologies". Imagination Technologies. Retrieved 2016-06-22.
- 1 2 MIPS R3000 Instruction Set Summary
- ↑ MIPS Instruction Reference
- ↑ ftp://ftp.linux-mips.org/pub/linux/mips/doc/ABI2/MIPS-N32-ABI-Handbook.pdf
- ↑ "OVP: Fast Simulation, Free Open Source Models. Virtual Platforms for software development". Ovpworld.org. Retrieved 2012-05-30.
- ↑ "Imperas". Imperas. 2008-03-03. Retrieved 2012-05-30.
- ↑ "EduMIPS64". Edumips.org. Retrieved 2012-05-30.
- ↑ "MARS MIPS simulator - Missouri State University". Courses.missouristate.edu. Retrieved 2012-05-30.
- ↑ http://www.maiconsoft.com.br/webmips/index.asp (online demonstration) http://www.dii.unisi.it/~giorgi/WEBMIPS/ (source)
Further reading
- Patterson, David A; John L. Hennessy. Computer Organization and Design: The Hardware/Software Interface. Morgan Kaufmann Publishers. ISBN 1-55860-604-1.
- Sweetman, Dominic. See MIPS Run, 2nd edition. Morgan Kaufmann Publishers. ISBN 0-12-088421-6.
- Sweetman, Dominic. See MIPS Run. Morgan Kaufmann Publishers. ISBN 1-55860-410-3.
- Farquhar, Erin; Philip Bunce. MIPS Programmer's Handbook. Morgan Kaufmann Publishers. ISBN 1-55860-297-6.
- Reverse Engineering for Beginners (including MIPS assembly); Dennis Yurichev; free online book.
External links
| Wikibooks has a book on the topic of: MIPS Assembly |
- Imagination Technologies
- MIPS Processors
- prpl foundation
- Patterson & Hennessy - Appendix A
- Summary of MIPS assembly language
- MIPS Instruction reference
- MARS (MIPS Assembler and Runtime Simulator)
- MIPS processor images and descriptions at cpu-collection.de
- A programmed introduction to MIPS assembly
- Mips bitshift operators
- MIPS software user's manual
- MIPS Architecture history diagram