Lontara alphabet
| Lontara ᨒᨚᨈᨑ | |
|---|---|
|
| |
| Type | |
| Languages | Buginese language, Makassarese language, Mandar language |
Time period | 17th century – present |
Parent systems | |
Sister systems |
Balinese Batak Baybayin Kulitan Buhid Hanunó'o Javanese Old Sundanese Rencong Rejang Tagbanwa |
| Direction | Left-to-right |
| ISO 15924 |
Bugi, 367 |
Unicode alias | Buginese |
| U+1A00–U+1A1F | |
The Lontara script is a Brahmic script traditionally used for the Bugis, Makassarese, and Mandar languages of Sulawesi in Indonesia. It is also known as the Buginese script, as Lontara documents written in this language are the most numerous. It was largely replaced by the Latin alphabet during the period of Dutch colonization, though it is still used today to a limited extent. The term Lontara is derived from the Malay name for palmyra palm, lontar, whose leaves are traditionally used for manuscripts. In Buginese, this script is called urupu sulapa eppa which means "four-cornered letters", referencing the Bugis-Makasar belief of the four elements that shaped the universe: fire, water, air, and earth.
History
Lontara is a descendant of the Kawi script, used in Maritime Southeast Asia around 800 CE. It is unclear whether the script is a direct descendant from Kawi, or derived from one of Kawi's other descendants. One theory states that it is modelled after the Rejang script, perhaps due to their graphical similarities. But this claim may be unfounded as some characters of the Lontara are a late development.[1]
The term Lontara has also come to refer to literature regarding Bugis history and genealogy, including the Sure’ Galigo creation myth. Historically, Lontara was also used for a range of documents including contracts, trade laws, treaties, maps, and journals. These documents are commonly written in a contemporary-like book form, but they can be written in a traditional palm-leaf manuscript also called Lontara, in which a long, thin strip of dried lontar is rolled to a wooden axis in similar manner to a tape recorder. The text is then read by scrolling the lontar strip from left to right.[2]
Although the Latin alphabet has largely replaced Lontara, it is still used to a limited extent in Bugis and Makasar. In Bugis, its usage is limited to ceremonial purposes such as wedding ceremonies. Lontara is also used extensively in printing traditional Buginese literature. In Makasar, Lontara is additionally used for personal documents such as letters and notes. Those who are skilled in writing the script are known as palontara, or 'writing specialists'.
Usage
Lontara is an abugida with 23 basic consonants. As of other Brahmic scripts, each consonant of Lontara carries an inherent /a/ vowel, pronounced /ɔ/ in Buginese (similar articulations are found in the Javanese script), which are changed via diacritics into one of the following vowels; /i/, /u/, /e/, /ə/, or /o/. However, Lontara do not have a virama, or other consonant-ending diacritics. Nasal /ŋ/, glottal /ʔ/, and gemination used in Buginese language are not written. As such, text can be highly ambiguous, even to native readers. For instance, ᨔᨑ can be read as sara 'sorrow', sara' 'rule', or sarang 'nest'.[3]
The Buginese people take advantage of this defective element of the script in language games called Basa to Bakke’ ᨅᨔ ᨈᨚ ᨅᨙᨀ ('Language of Bakke’ people') and Elong maliung bəttuanna ᨕᨒᨚ ᨆᨒᨗᨕᨘ ᨅᨛᨈᨘᨕᨊ (literally 'song with deep meaning') riddles.[4] Basa to Bakke’ is similar to punning, where words with different meanings but same spelling are manipulated to come up with phrases that have hidden message. This is similar to Elong maliung bettuanna, in which audience are asked to figure the correct pronunciation of a meaningless poem to reveal the poem's hidden message.
Lontara is written from left to right, but it can also be written boustrophedonically. This method is mostly applied in old Buginese journals, in which each page are reserved for record of one day. If a scribe ran out of writing space for one day's log, the continuing line would be written sideways to the page, following a zig-zag pattern until all space are filled.[5]

Form

The contemporary Lontara script is distinctively angular compared to other Brahmic scripts, succeeding from two older, less angular variant called Toa jangang-jangang and Bilang-bilang. Lontara are written without word space (scriptio continua).
Consonants
The consonants (indo’ surə’ ᨕᨗᨉᨚ ᨔᨘᨑᨛ or ina’ surə’ ᨕᨗᨊ ᨔᨘᨑᨛ) consist of 23 letters. Like other Indic abugidas, each consonant represents a syllable with the inherent vowel /a/, which is pronounced /ɔ/ in Buginese.
| ka | ga | nga | ngka | pa | ba | ma | mpa | ta | da | na | nra |
| /ka/ | /ga/ | /ŋa/ | /ŋka/ | /pa/ | /ba/ | /ma/ | /mpa/ | /ta/ | /da/ | /na/ | /nra/ |
 | 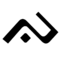 |  |  | 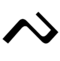 |  |  |  |  |  |  |  |
| ᨀ | ᨁ | ᨂ | ᨃ | ᨄ | ᨅ | ᨆ | ᨇ | ᨈ | ᨉ | ᨊ | ᨋ |
| ca | ja | nya | nca | ya | ra | la | wa | sa | a | ha | |
| /ca/ | /ɟa/ | /ɲa/ | /ɲca/ | /ja/ | /ra/ | /la/ | /wa/ | /sa/ | /a/ | /ha/ | |
 |  | | | |  | | |  | | | |
| ᨌ | ᨍ | ᨎ | ᨏ | ᨐ | ᨑ | ᨒ | ᨓ | ᨔ | ᨕ | ᨖ |

As previously mentioned, Lontara does not feature a vowel killer mark, like halant or virama common among Indic scripts. Nasal /ŋ/, glottal /ʔ/, and gemination used in Buginese language are not written (with the exception of accidental initial glottal stops, which are written with the null consonant "a").
Four frequent consonant clusters however, are denoted with specific letters. These are ngka ᨃ, mpa ᨇ, nra ᨋ and nca ᨏ. "Nca" actually represents the sound "nyca" (/ɲca/), but often transcribe only as "nca". Those letters are not used in the Makassarese language . The letter ha ᨖ is a new addition to the script for the glottal fricative due to the influence of the Arabic language.
Vowels
The diacritic vowels (ana’ surə’ ᨕᨊ ᨔᨘᨑᨛ) are used to change the inherent vowel of the consonants. There are 5 ana’ surə’, with /ə/ not used in the Makassarese language (which does not make a phonological distinction with the inherent vowel). Graphically, they can be divided into two subsets; dots (tətti’) and accents (kəccə’).[6]
| — | Tətti’ riasə’ | Tətti’ riawa | kəccə’ riolo | kəccə’ riasə’ | kəccə’ rimunri |
| /a/ | /i/ | /u/ | /e/ | /ə/ | /o/ |
 |  |  |  |  | |
| ᨀ | ᨀᨗ | ᨀᨘ | ᨀᨙ | ᨀᨛ | ᨀᨚ |
| | | | | | |
Additionally, the third vowel [e] must appear before (to the left) the consonant that it modifies, but must remain logically encoded after that consonant, in conforming Unicode implementations of fonts and text renderers (this case of prepended vowels which occurs in many Indic scripts, does not follow the exception to the Unicode logical encoding order, admitted only for the prepended vowels in the Thai, Lao and Tai Viet scripts). Currently, many fonts or text renderers do not implement this single reordering rule for the Buginese script, and may still incorrectly display that vowel at the wrong position.
Other diacritics
To transcribe foreign words as well as reducing ambiguity, recent Buginese fonts includes three diacritics that suppress inherent vowel (virama), nasalize vowel (anusvara), and mark glottal end or geminated consonant, depending on the position. These diacritics do not exist in traditional Lontara and are not included into Unicode, but has gained currency among Buginese experts, such as Mr Djirong Basang, who worked with the Monotype Typography project to prepare the Lontara fonts used in the LASERCOMP photo typesetting machine.[7]
| virama | anusvara | glottal |
 |  |  |
Punctuation
| pallawa | end section |
 |  |
| ᨞ | ᨟ |
Pallawa is used to separate rhythmico-intonational groups, thus functionally corresponds to the period and comma of the Latin script. The pallawa can also be used to denote the doubling of a word or its root.
Encoding
Unicode
Buginese was added to the Unicode Standard in March, 2005 with the release of version 4.1.
The Unicode block for Buginese is U+1A00–U+1A1F:
| Buginese[1][2] Official Unicode Consortium code chart (PDF) | ||||||||||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | A | B | C | D | E | F | |
| U+1A0x | ᨀ | ᨁ | ᨂ | ᨃ | ᨄ | ᨅ | ᨆ | ᨇ | ᨈ | ᨉ | ᨊ | ᨋ | ᨌ | ᨍ | ᨎ | ᨏ |
| U+1A1x | ᨐ | ᨑ | ᨒ | ᨓ | ᨔ | ᨕ | ᨖ | ◌ᨗ | ◌ᨘ | ᨙ◌ | ◌ᨚ | ◌ᨛ | ᨞ | ᨟ | ||
| Notes | ||||||||||||||||
Sorting order
- The Lontara block for Unicode use Matthes' order, in which prenasalized consonants are placed after corresponding nasal consonant, similar to how aspirated consonant would be placed following its unaspirated counterpart in standard Sanskrit. Matthes' order however, does not follow traditional Sanskrit sequence except for the first three of its consonants.
- ᨀ ᨁ ᨂ ᨃ ᨄ ᨅ ᨆ ᨇ ᨈ ᨉ ᨊ ᨋ ᨌ ᨍ ᨎ ᨏ ᨐ ᨑ ᨒ ᨓ ᨔ ᨕ ᨖ
- Lontara consonants can also be sorted or grouped according to their base shapes:
- Consonant ka ᨀ
- Consonant pa ᨄ and based on it: ga ᨁ, mpa ᨇ, nra ᨋ
- Consonant ta ᨈ and based on it: na ᨊ, ngka ᨃ, nga ᨂ, ba ᨅ, ra ᨑ, ca ᨌ, ja ᨍ, sa ᨔ
- Consonant ma ᨆ and based on it: da ᨉ
- Consonant la ᨒ
- Consonant wa ᨓ and based on it: ya ᨐ, nya ᨎ, nca ᨏ, ha ᨖ, a ᨕ
Rendering issues
To get the correct display of the prepended vowel [e], installing a font conforming to the standard Unicode encoding of the Buginese script is not enough, because you also need either:
- a text renderer whose layout/shaping engine internally reorders the glyph mapped from the vowel [e] before the glyph mapped from consonants, and a basic font containing a spacing glyph for that vowel; such approach will be used with TrueType and OpenType fonts, without needing any OpenType layout table in that font; there already exist such fonts, but still not any compatible OpenType layout engine, because it must contain a specific code to support the Buginese script (compliant TrueType fonts for the Buginese script already exist, such as Saweri or Code2000, but the Uniscribe layout engine used by most versions of Microsoft Windows still does not have this support (integrated only in Windows Server 2012 R2 and Windows 8.1), so the Buginese script still cannot be used in Microsoft Word and Internet Explorer; but alternate layout engines for OpenType may be used in other word processors and web browsers, provided that these text layout engines are also updated to support the script: this includes the Pango text layout engine currently ported on Linux, Windows, OS X, and some other platforms, but which currently lacks this necessary support);
- a text renderer that does not implement the reordering and works in a script-neutral way, but that can support complex scripts with a text layout/shaping engine capable of rendering complex scripts only through fonts specially built to include advanced layout/shaping tables, and a font that contains these layout tables; such a renderer exists on OS X, which uses the AAT engine, but the existing Buginese fonts do not contain AAT layout tables (with the exception of some commercial Buginese fonts designed and sold by some font foundries specifically for the OS X platform[8]), so the expected reordering of vowel [e] will not be rendered.
As a consequence, there is still no complete support for this Buginese script in most major Operating Systems and applications.
And the script can only be rendered correctly, temporarily, using either:
- tweaked fonts, specific for each platform and without a warranty of stability across OS versions and applications;
- encoding Buginese texts in a way not conforming to the Unicode standard, for example encoding texts with the vowel [e] before the consonant (also without warranty of stability for the future, when conforming fonts and text renderers will be available, because they will then reorder the vowel [e] with any consonant encoded before that vowel; this solution also does not work as it already creates the incorrect grapheme cluster boundaries, the vowel being already grouped with the previous character instead of the following, notably in text editors);
- specially encoding in Unicode the Buginese vowel [e] in such a way that it will never be reordered by a layout engine (conforming or not), for example by encoding this vowel after a non-breaking space (to make it appear in isolation) but still before the consonant (in visual order), provided that the font or layout engine correctly renders this combination (most layout engines support this universal convention displaying combining marks and diacritic character in isolation); this implies an orthographic change in texts (the vowel is no longer logically associated to any consonant, so full text searches and text correctors would need to also look for such isolated vowel occurring before a consonant), and additional complexities for users trying to enter Buginese texts.
For example, the normal and expected encoding of the Buginese syllable ke in texts conforming to the Unicode standard (encoded in logical order) is
- U+1A00 BUGINESE LETTER KA ᨀ — this is the base character of the grapheme cluster,
- U+1A19 BUGINESE VOWEL SIGN E ᨙ◌ — the vowel sign should be prepended (to the left of the dotted circle placeholder),
which currently renders as ᨀᨙ (this rendering will currently be wrong with many old browsers or on old versions of Windows).
With the third solution above (which is technically still conforming to the Unicode standard, but is logically a distinct orthography using two separate grapheme clusters, which would normally be logically interpreted as (e)ka instead of the plain syllable ke, even if it visually reads as ke), it could instead be specially encoded in tweaked texts (in visual order) as:
- U+00A0 NON-BREAKING SPACE — this is the base character of a first grapheme cluster,
- U+1A19 BUGINESE VOWEL SIGN E ᨙ◌ — the vowel sign should be prepended (to the left of the dotted circle placeholder),
- U+1A00 BUGINESE LETTER KA ᨀ — this is the base character of a second grapheme cluster,
which should now render correctly as ᨙᨀ (but note the possible larger left-side and/or right-side bearings around the vowel, which is now shown in isolation separately from the following letter ka, and in the middle of a non-breaking space which may itself be larger than the diacritic; this may be corrected in fonts, by including a single kerning pair for the vowel occurring after a whitespace). Although this solution is not ideal for the long term, text indexers may be adapted for compatibility of this encoding with the recommended encoding exposed in the previous paragraph, by considering this character triple as semantically equivalent as the previous character pair; and future fonts and text layout engines could also render this triple by implementing a non-discretionnary ligature between the two graphemes, so that it will render exactly like the standard character pair (which uses a single grapheme cluster).
There still remains problems with fonts that have minimum coverage in their mapping, because text renderers still not correctly reorder the isolated Buginese vowel e when it follows something else than NBSP or a Buginese consonant (for example when it follows the standard U+0020 SPACE, or the U+25CC DOTTED CIRCLE symbolic placeholder, as recommended in OpenType designs), or because fonts do not have correct kerning rules for additional pairs using any one of the 5 Buginese vowel signs.
Sample texts

An extract from Latoa
| ᨊᨀᨚ | ᨕᨛᨃ | ᨈᨕᨘᨄᨔᨒ᨞ | ᨕᨍ | ᨆᨘᨄᨈᨒᨒᨚᨓᨗ | ᨄᨌᨒᨆᨘ | ᨑᨗᨈᨚᨄᨔᨒᨕᨙ᨞ |
| Nako | əŋka | taupasala, | aja | mupatalalowi | pacalamu | ritopasalae. |
| If | you deal with | a person guilty of something, | do not | punish him | too harshly. | |
| ᨄᨔᨗᨈᨘᨍᨘᨓᨗᨆᨘᨈᨚᨓᨗᨔ | ᨕᨔᨒᨊ | ᨄᨌᨒᨆᨘ᨞ | ᨕᨄ | ᨕᨗᨀᨚᨊᨈᨘ | ᨊᨁᨗᨒᨗ | ᨉᨙᨓᨈᨕᨙ᨞ |
| Pasitujuwimutowisa | asalana | pacalamu, | apa | ikonatu | nagili | dewatae, |
| Always make the | punishment commensurable with the guilt, | since | God will be angry with you, | |||
| ᨊᨀᨚ | ᨅᨕᨗᨌᨘᨆᨘᨄᨗ | ᨕᨔᨒᨊ | ᨈᨕᨘᨓᨙ᨞ | ᨆᨘᨄᨙᨑᨍᨕᨗᨔ | ᨄᨉᨈᨚᨓᨗ᨞ |
| nako | baicumupi | asalana | tauwe, | muperajaisa | padatowi. |
| if | the person's | guilt is not great and | you are exaggerating it. | ||
| ᨊᨀᨚ | ᨄᨔᨒᨕᨗ | ᨈᨕᨘᨓᨙ᨞ | ᨕᨍ | ᨈᨗᨆᨘᨌᨒᨕᨗ | ᨑᨗᨔᨗᨈᨗᨊᨍᨊᨕᨙᨈᨚᨔ | ᨕᨔᨒᨊ᨞ |
| Nako | pasalai | tauwe, | aja | timucalai | risitinajanaetosa | asalana. |
| If | a person is guilty, | do not | let him go without a punishment in accordance with | his guilt. | ||
What is this text?
| ᨕᨛᨛᨃ | ᨕᨛᨃ | ᨄ ᨙᨑ᨞ | ᨕᨛᨃ | ᨙᨔᨕᨘᨓ | ᨓᨛᨈᨘ᨞ |
| Əŋka | əŋka | ɡare, | əŋka | seuwa | wəttu, |
| Once there was | a story, | once upon | a time, | ||
| ᨕᨛᨃ | ᨙᨔᨕᨘᨓ | ᨕᨑᨘ | ᨆᨀᨘᨋᨕᨗ | ᨑᨗ | ᨒᨘᨓᨘ᨞ | ᨆᨔᨒ | ᨕᨘᨒᨗ᨞ |
| əŋka | seuwa | aruŋ | makunraï | ri | Luwu, | masala | uli. |
| about a | princess | in | Luwu, | with leprosy. | |||
See also
References
- ↑ J. Noorduyn (1993). "Variation in the Bugis/Makasarese script". Bijdragen tot de Taal-, Land- en Volkenkunde. KITLV, Royal Netherlands Institute of Southeast Asian and Caribbean Studies (149): 533–570.
- ↑ http://wacananusantara.org/lontaraq-dan-aksara-lontara-aksara-bugis/
- ↑ R. Tol (1992). Fish food on a tree branch; Hidden meanings in Bugis poetry
- ↑ R. Tol (1992). Fish food on a tree branch; Hidden meanings in Bugis poetry, "Basa To Bakkeq".
- ↑ John McGlynn (2003), Indonesian Heritage – Vol 10 – Language & Literature
- ↑ "Lontara' Ugi « Dunia Kata-Kata Ku". Chimutluchu.wordpress.com. 2010-04-09. Retrieved 2012-11-21.
- ↑ http://std.dkuug.dk/jtc1/sc2/wg2/docs/n2633r.pdf
- ↑ Unicode Lontara (Bugis) Language Kit for OSX, by XenoType Technology, includes an OpenType/CFF font with feature tables designed to work with Apple Advanced Typography (AAT), which allows rendering Buginese and Makkasarese texts written with the Lontara script and encoded in a Unicode-compliant logical order.
- Campbell, George L. (1991). Compendium of the World's Languages. Routledge. pp. 267–273.
- Daniels, Peter T.; Bright, William (1996). The World's Writing Systems. Oxford University Press. pp. 474, 480.
- Dalby, Andrew (1998). Dictionary of Languages: The Definitive Reference to More Than 400 Languages. Columbia University Press. pp. 99–100, 384.
- Sirk, Ü; Shkarban, Lina Ivanovna (1983). The Buginese Language. USSR Academy of Sciences, Institute of Oriental Studies: Nauka Publishing House, Central Department of Oriental Literature. pp. 24–26, 111–112.
External links
| Wikimedia Commons has media related to Lontara alphabet. |
| Wikimedia Commons has media related to Buginese script. |
- Lontara and Makasar scripts
- Article about Buginese script in JSTOR
- http://unicode-table.com/en/sections/buginese/
- Buginese script on www.ancientscripts.com
- Saweri, a font that supports only lontara script. (This font is Truetype-only, and will not properly reorder the prepended vowel /e/ to the left without the help of a compliant text-layout engine, still missing)
- Revised final proposal for encoding the Lontara (Buginese) script in the UCS, by Michael Everson (2003). Detailed description of the graphical features of the script, needed in conforming fonts (including a ligature), submitted to the ISO TC2 and Unicode working committee prior to the final encoding of the Bugis/Lontara script in the UCS. Note that this document describes a few other characters that were not encoded in the final release of Unicode 4.1 where the script was encoded (notably a vowel killer or virama, found in some transcriptions to disambiguate the script, a diacritic for annotating the gemination of consonants, an anusvara sign for noting the vowelless ng, and a few other punctuation symbols).