Druid (open-source data store)
 | |
| Original author(s) | Eric Tschetter, Fangjin Yang |
|---|---|
| Developer(s) | The Druid community |
| Stable release |
0.9.1.1
/ 29 June 2016 |
| Repository |
github |
| Development status | Active |
| Written in | Java |
| Operating system | Cross-platform |
| Type | distributed, real-time, column-oriented data store |
| License | Apache License 2.0 |
| Website |
druid |
Druid is a column-oriented, open-source, distributed data store written in Java. Druid is designed to quickly ingest massive quantities of event data, and provide low-latency queries on top of the data.[1] The name Druid comes from the shapeshifting Druid class in many role-playing games, to reflect the fact that the architecture of the system can shift to solve different types of data problems.
Druid is commonly used in business intelligence/OLAP applications to analyze high volumes of real-time and historical data.[2] Druid is used in production by technology companies such as Alibaba,[3] Airbnb,[4] Cisco,[5] eBay,[6] Netflix,[7] Paypal,[8] and Yahoo.[9]
History
Druid was started in 2011 to power the analytics product of a company named Metamarkets. The project was open-sourced under the GPL license in October 2012,[10][11] and moved to an Apache License in February 2015.[12][13]
Over time, a number of organizations and companies have integrated Druid into their backend technology,[14] and committers have been added from numerous different organizations.[15]
In October 2015, the commercial company Imply launched to provide enterprise level support and professional services for Druid.[16]
Architecture
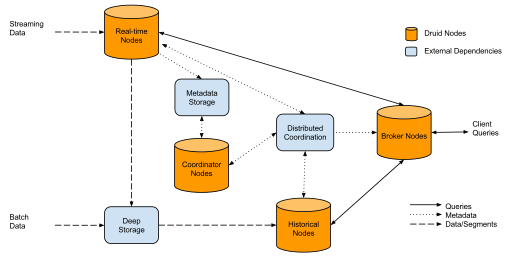
Fully deployed, Druid runs as a cluster of specialized processes (called nodes in Druid) to support a fault-tolerant architecture[17] where data is stored redundantly, and there is no single point of failure.[18] The cluster includes external dependencies for coordination (Apache ZooKeeper), metadata storage (e.g. MySQL, PostgreSQL, or Derby), and a deep storage facility (e.g. HDFS, or Amazon S3) for permanent data backup.
Query Management
Client queries first hit broker nodes, which forward them to the appropriate data nodes (either historical or real-time). Since Druid segments may be partitioned, an incoming query can require data from multiple segments and partitions (or shards) stored on different nodes in the cluster. Brokers are able to learn which nodes have the required data, and also merge partial results before returning the aggregated result.
Cluster Management
Operations relating to data management in historical nodes are overseen by coordinator nodes. Apache ZooKeeper is used to register all nodes, manage certain aspects of internode communications, and provide for leader elections.
Features
- Low latency (streaming) data ingestion
- Arbitrary slice and dice data exploration
- Sub-second analytic queries
- Approximate and exact computations
References
- ↑ Hemsoth, Nicole. "Druid Summons Strength in Real-Time", Datanami, 08 November 2012
- ↑ druid. "Druid | Powered by Druid". druid.io. Retrieved 2016-06-29.
- ↑ druid. "Druid | Powered by Druid". druid.io. Retrieved 2016-06-23.
- ↑ druid. "Druid | Powered by Druid". druid.io. Retrieved 2016-06-23.
- ↑ Butler, Brandon. "Under the hood of Cisco's Tetration Analytics platform". Retrieved 2016-06-23.
- ↑ "Druid at Pulsar - ebay的专栏 - 博客频道 - CSDN.NET". blog.csdn.net. Retrieved 2016-06-23.
- ↑ "The Netflix Tech Blog: Announcing Suro: Backbone of Netflix's Data Pipeline". techblog.netflix.com. Retrieved 2016-06-23.
- ↑ druid. "Druid | Powered by Druid". druid.io. Retrieved 2016-06-23.
- ↑ "Complementing Hadoop at Yahoo: Interactive Analytics with Druid". Retrieved 2016-06-23.
- ↑ Tschetter, Eric. "Introducing Druid", Druid.io, 24 October 2012
- ↑ Higginbotham, Stacey. "Metamarkets open sources Druid, its in-memory database", GigaOM, 24 October 2012
- ↑ Harris, Derrick (2015-02-20). "The Druid real-time database moves to an Apache license". Retrieved 2015-08-04.
- ↑ "Druid Gets Open Source-ier Under the Apache License". Retrieved 2015-08-04.
- ↑ druid. "Druid | Powered by Druid". druid.io. Retrieved 2016-06-23.
- ↑ druid. "Druid | Druid Community". druid.io. Retrieved 2016-06-23.
- ↑ Novet, Jordan. "Imply launches with $2M to commercialize the Druid open-source data store", VentureBeat, 19 October 2015
- ↑ Druid Project Documentation
- ↑ Yang, Fangjin; Tschetter, Eric; Léauté, Xavier; Ray, Nelson; Merlino, Gian; Ganguli, Deep. "Druid: A Real-time Analytical Data Store", Metamarkets, retrieved 6 February 2014