Chinese character classification
All Chinese characters are logograms, but several different types can be identified, based on the manner in which they are formed or derived. There are a handful which derive from pictographs (象形 pinyin: xiàngxíng) and a number which are ideographic (指事 zhǐshì) in origin, including compound ideographs (會意 huìyì), but the vast majority originated as phono-semantic compounds (形聲 xíngshēng). The other categories in the traditional system of classification are rebus or phonetic loan characters (假借 jiǎjiè) and "derivative cognates" (轉注 zhuǎn zhù). Modern scholars have proposed various revised systems, rejecting some of the traditional categories.
In older literature, Chinese characters in general may be referred to as ideograms, due to the misconception that characters represented ideas directly, whereas in fact they do so only through association with the spoken word.[1]
Traditional classification
Traditional Chinese lexicography divided characters into six categories (六書 liùshū "Six Writings"). This classification is known from Xu Shen's second century dictionary Shuowen Jiezi, but did not originate there. The phrase first appeared in the Rites of Zhou, though it may not have originally referred to methods of creating characters. When Liu Xin (d. 23 CE) edited the Rites, he glossed the term with a list of six types without examples.[2] Slightly different lists of six types are given in the Book of Han of the first century CE, and by Zheng Zhong quoted by Zheng Xuan in his first-century commentary on the Rites of Zhou. Xu Shen illustrated each of Liu's six types with a pair of characters in the postface to the Shuowen Jiezi.[3]
The traditional classification is still taught but is no longer the focus of modern lexicographic practice. Some categories are not clearly defined, nor are they mutually exclusive: the first four refer to structural composition, while the last two refer to usage. For this reason, some modern scholars view them as six principles of character formation rather than six types of characters.
The earliest significant, extant corpus of Chinese characters is found on turtle shells and the bones of livestock, chiefly the scapula of oxen, for use in pyromancy, a form of divination. These ancient characters are called oracle bone script. Roughly a quarter of these characters are pictograms while the rest are either phono-semantic compounds or compound ideograms. Despite millennia of change in shape, usage and meaning, a few of these characters remain recognizable to the modern reader of Chinese.
At present, more than 90% of Chinese characters are phono-semantic compounds, constructed out of elements intended to provide clues to both the meaning and the pronunciation. However, as both the meanings and pronunciations of the characters have changed over time, these components are no longer reliable guides to either meaning or pronunciation. The failure to recognize the historical and etymological role of these components often leads to misclassification and false etymology. A study of the earliest sources (the oracle bones script and the Zhou-dynasty bronze script) is often necessary for an understanding of the true composition and etymology of any particular character. Reconstructing Middle and Old Chinese phonology from the clues present in characters is part of Chinese historical linguistics. In Chinese, it is called Yinyunxue (音韻學 "Studies of sounds and rimes").
Pictograms
Roughly 600 Chinese characters are pictograms (象形 xiàng xíng, "form imitation") — stylised drawings of the objects they represent. These are generally among the oldest characters. A few, indicated below with their earliest forms, date back to oracle bones from the twelfth century BCE.
These pictograms became progressively more stylized and lost their pictographic flavor, especially as they made the transition from the oracle bone script to the Seal Script of the Eastern Zhou, but also to a lesser extent in the transition to the clerical script of the Han Dynasty. The table below summarises the evolution of a few Chinese pictographic characters. Where no modern simplified form is provided, it is identical to the traditional character.















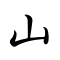

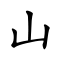
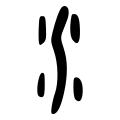


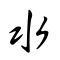




















































































N.B.:
- 水 shuǐ "water" represents the lines of a flowing river.
Simple ideograms
Ideograms (指事 zhǐ shì, "indication") express an abstract idea through an iconic form, including iconic modification of pictographic characters. In the examples below, low numerals are represented by the appropriate number of strokes, directions by an iconic indication above and below a line, and the parts of a tree by marking the appropriate part of a pictogram of a tree.
| Character | 一 |
二 |
三 |
上 |
下 |
本 |
末 |
|---|---|---|---|---|---|---|---|
| Pinyin | yī | èr | sān | shàng | xià | běn | mò |
| Gloss | one | two | three | up | below | root | apex |
N.B.:
- 本 běn "root" - a tree (木 mù) with the base indicated by an extra stroke.
- 末 mò "apex" - the reverse of 本 (běn), a tree with the top highlighted by an extra stroke.
Compound ideographs
Compound ideographs (會意 huì yì, "joined meaning"), also called associative compounds or logical aggregates, are compounds of two or more pictographic or ideographic characters to suggest the meaning of the word to be represented. In the postface to the Shuowen Jiezi, Xu Shen gave two examples:[3]
- 武 "military", formed from 戈 "dagger-axe" and 止 "foot"
- 信 "truthful", formed from 人 "person" (later reduced to 亻) and 言 "speech"
Other characters commonly explained as compound ideographs include:
- 林 lín "grove", composed of two trees[4]
- 森 sēn "forest", composed of three trees[5]
- 休 xiū "shade, rest", depicting a man by a tree[6]
- 采 cǎi "harvest", depicting a hand on a bush (later written 採)[7]
- 看 kàn "watch", depicting a hand above an eye[8]
- 莫 mù "sunset", depicting the sun disappearing into the grass, originally written as 茻 "thick grass" enclosing 日 (later written 暮)[9]
Many characters formerly classed as compound ideographs are now believed to have been mistakenly identified. For example, Xu Shen's example 信, representing the word xìn < *snjins "truthful", is now usually considered a phono-semantic compound, with 人 rén < *njin as phonetic and 言 "speech" as signific.[2][10] In many cases, reduction of a character has obscured its original phono-semantic nature. For example, the character 明 "bright" is often presented as a compound of 日 "sun" and 月 "moon". However this form is probably a simplification of an attested alternative form 朙, which can be viewed as a phono-semantic compound.[11]
Peter Boodberg and William Boltz have argued that no ancient characters were compound ideographs. Boltz accounts for the remaining cases by suggesting that some characters could represent multiple unrelated words with different pronunciations, as in Sumerian cuneiform and Egyptian hieroglyphs, and the compound characters are actually phono-semantic compounds based on an alternative reading that has since been lost. For example, the character 安 ān < *ʔan "peace" is often cited as a compound of 宀 "roof" and 女 "woman". Boltz speculates that the character 女 could represent both the word nǚ < *nrjaʔ "woman" and the word ān < *ʔan "settled", and that the roof signific was later added to disambiguate the latter usage. In support of this second reading, he points to other characters with the same 女 component that had similar Old Chinese pronunciations: 妟 yàn < *ʔrans "tranquil", 奻 nuán < *nruan "to quarrel" and 姦 jiān < *kran "licentious".[12] Other scholars reject these arguments for alternative readings and consider other explanations of the data more likely, for example viewing 妟 as a reduced form of 晏, which can be analysed as a phono-semantic compound with 安 as phonetic. They consider the characters 奻 and 姦 to be implausible phonetic compounds, both because the proposed phonetic and semantic elements are identical and because the widely differing initial consonants *ʔ- and *n- would not normally be accepted in a phonetic compound.[13] Notably, Christopher Button has shown how more sophisticated palaeographical and phonological analyses can account for Boodberg's and Boltz's proposed examples without relying on polyphony.[14]
While compound ideographs are a limited source of Chinese characters, they form many of the kokuji created in Japan to represent native words. Examples include:
- 働 hatara(ku) "to work", formed from 人 "person" and 動 "move"
- 峠 tōge "mountain pass", formed from 山 "mountain", 上 "up" and 下 "down"
As Japanese creations, such characters had no Chinese or Sino-Japanese readings, but a few have been assigned invented Sino-Japanese readings. For example, the common character 働 has been given the reading dō (taken from 動), and even been borrowed into written Chinese in the 20th century with the reading dòng.[15]
Rebus (phonetic loan) characters
Jiajie (假借 jiǎjiè, "borrowing; making use of") are characters that are "borrowed" to write another homophonous or near-homophonous morpheme. For example, the character 來 was originally a pictogram of a wheat plant and meant *mlək "wheat". As this was pronounced similarly to the Old Chinese word *lai "to come", 來 was also used to write this verb. Eventually the more common usage, the verb "to come", became established as the default reading of the character 來, and a new character 麥 was devised for "wheat". (The modern pronunciations are lái and mài.) When a character is used as a rebus this way, it is called a jiajiezi 假借字 (lit. "loaned and borrowed character") (in Wade-Giles "chia-chie" or "chia-chieh"), translatable as "phonetic loan character" or "rebus" character.
As in Egyptian hieroglyphs and Sumerian cuneiform, early Chinese characters were used as rebuses to express abstract meanings that were not easily depicted. Thus many characters stood for more than one word. In some cases the extended use would take over completely, and a new character would be created for the original meaning, usually by modifying the original character with a radical (determinative). For instance, 又 yòu originally meant "right hand; right" but was borrowed to write the abstract word yòu "again; moreover". In modern usage, the character 又 exclusively represents yòu "again" while 右, which adds the "mouth radical" 口 to 又, represents yòu "right". This process of graphic disambiguation is a common source of phono-semantic compound characters.
| Pictograph or ideograph | Rebus word | Original word | New character for original word |
|---|---|---|---|
| 四 | sì "four" | sì "nostrils" | 泗 (mucous; sniffle) |
| 枼 | yè "flat, thin" | yè "leaf" | 葉 |
| 北 | běi "north" | bèi "back (of the body)" | 背 |
| 要 | yào "to want" | yāo "waist" | 腰 |
| 少 | shǎo "few" | shā "sand" | 沙 and 砂 |
| 永 | yǒng "forever" | yǒng "swim" | 泳 |
While this word jiajie dates from the Han Dynasty, the related term tongjia (通假 tōngjiǎ "interchangeable borrowing") is first attested from the Ming Dynasty. The two terms are commonly used as synonyms, but there is a linguistic distinction between jiajiezi being a phonetic loan character for a word that did not originally have a character, such as using 東 "a bag tied at both ends"[16] for dōng "east", and tongjia being an interchangeable character used for an existing homophonous character, such as using 蚤 zǎo "flea" for 早 zǎo "early".
According to Bernhard Karlgren, "One of the most dangerous stumbling-blocks in the interpretation of pre-Han texts is the frequent occurrence of [jiajie], loan characters."[17]
Phono-semantic compound characters
- 形聲 xíng shēng "form and sound" or 諧聲 xié shēng "sound agreement"
These are often called radical-phonetic characters. They form the majority of Chinese characters by far—over 90%, and were created by combining a rebus with a determinative—that is, a character with approximately the correct pronunciation (the phonetic element, similar to a phonetic complement) with one of a limited number of determinative characters which supplied an element of meaning (the semantic element, which in most cases is also the radical under which a character is listed in a dictionary). As in ancient Egyptian writing, such compounds eliminated the ambiguity caused by phonetic loans (above).
Most often, the radical is on one side (often the left), while the phonetic is on the other side (often the right), as in 沐 = 氵 "water" + 木 mù. Also common is for the semantic and phonetic elements to be stacked on top of each other, as in 菜 = 艹 "plant" + 采 cǎi. More rarely, the phonetic may be placed inside the semantic, as in 園 = 囗 "enclosure" + 袁, or 街 = 行 "go, movement" + 圭. More complicated combinations also exist, such as 勝 = 力 "strength" + 朕, where the semantic is in the lower-right quadrant, and the phonetic is the other three quadrants.
This process can be repeated, with a phono-semantic compound character itself being used as a phonetic in a further compound, which can result in quite complex characters, such as 劇 (豦 = 虍 + 豕, 劇 = 刂 + 豦).
Examples
As an example, a verb meaning "to wash oneself" is pronounced mù. Although difficult to draw, it happens to sound the same as the word mù "tree", which was written with the simple pictograph 木. The verb mù could simply have been written 木, like "tree", but to disambiguate, it was combined with the character for "water", giving some idea of the meaning. The resulting character eventually came to be written 沐 mù "to wash one's hair". Similarly, the water determinative was combined with 林 lín "woods" to produce the water-related homophone 淋 lín "to pour".
| Determinative | Rebus | Compound |
|---|---|---|
| 氵 water |
木 mù |
沐 mù "to wash oneself" |
| 氵 water |
林 lín |
淋 lín "to pour" |
However, the phonetic component is not always as meaningless as this example would suggest. Rebuses were sometimes chosen that were compatible semantically as well as phonetically. It was also often the case that the determinative merely constrained the meaning of a word which already had several. 菜 cài "vegetable" is a case in point. The determinative 艹 for plants was combined with 采 cǎi "harvest". However, 采 cǎi does not merely provide the pronunciation. In classical texts it was also used to mean "vegetable". That is, 采 underwent semantic extension from "harvest" to "vegetable", and the addition of 艹 merely specified that the latter meaning was to be understood.
| Determinative | Rebus | Compound |
|---|---|---|
| 艹 plant |
采 cǎi "harvest, vegetable" |
菜 cài "vegetable" |
Some additional examples:
| Determinative | Rebus | Compound |
|---|---|---|
| 扌 hand |
白 bái |
拍 pāi "to clap, to hit" |
| 穴 to dig into |
九 jiǔ |
究 jiū "to investigate" |
| 日 sun |
央 yāng |
映 yìng "reflection" |
Sound change
Originally characters sharing the same phonetic had similar readings, though they have now diverged substantially. Linguists rely heavily on this fact to reconstruct the sounds of Old Chinese – see historical Chinese phonology. Contemporary foreign pronunciations (Sino-Xenic pronunciations) of characters are also used to reconstruct older Chinese, chiefly Middle Chinese.
When people try to read a two-part character of which they are ignorant, they will typically follow the folk wisdom of you bian du bian (有邊讀邊) "read the side" and take one component to be a phonetic, which often results in errors.
Simplification
Since the phonetic elements of many characters no longer accurately represent their pronunciations, when the People's Republic of China simplified characters, they often substituted a phonetic that was not only simpler to write, but more accurate for a modern reading in Mandarin as well. This has sometimes resulted in forms which are less phonetic than the original ones in varieties of Chinese other than Mandarin. (Note for the example that many determinatives were simplified as well, usually by standardizing cursive forms.)
|
| |||||||||||||||
Derivative cognates
The derivative cognate (轉注 zhuǎn zhù, "reciprocal meaning") is the smallest category and also the least understood.[18] In the postface to the Shuowen Jiezi, Xu Shen gave as an example the characters 考 kǎo "to verify" and 老 lǎo "old", which had similar Old Chinese pronunciations (*khuʔ and *C-ruʔ respectively[19]) and may have had the same etymological root, meaning "elderly person", but became lexicalized into two separate words. The term does not appear in the body of the dictionary, and may have been included in the postface out of deference to Liu Xin.[20] It is often omitted from modern systems.
Modern classifications
The liushu had been the standard classification scheme for Chinese characters since Xu Shen's time. Generations of scholars modified it without challenging the basic concepts. Tang Lan (唐蘭) (1902–1979) was the first to dismiss liushu, offering his own sanshu (三書 "Three Principles of Character Formation"), namely xiangxing (象形 "form-representing"), xiangyi (象意 "meaning-representing") and xingsheng (形聲 "meaning-sound"). This classification was later criticised by Chen Mengjia (1911–1966) and Qiu Xigui. Both Chen and Qiu offered their own sanshu.[21]
See also
- Radical
- Chinese writing
- Chinese calligraphy
- Japanese writing
- Stroke order
- Ateji, Chinese characters used phonetically in Japanese
- Transliteration into Chinese characters, Chinese characters used phonetically
- Xiesheng series
References
- ↑ Hansen 1993.
- 1 2 Sampson & Chen 2013, p. 261.
- 1 2 Wilkinson 2013, p. 35.
- ↑ Qiu 2000, pp. 54, 198.
- ↑ Qiu 2000, p. 198.
- ↑ Qiu 2000, pp. 209–211.
- ↑ Qiu 2000, pp. 188, 226, 255.
- ↑ 《說文》: 睎也。从手下目。 《說文解字注》:宋玉所謂揚袂障日而望所思也。此會意。
- ↑ 《說文》: 日且冥也。从日在茻中。 Duan claims that this character is simultaneously also phono-semantic with 茻 mǎng as the phonetic: 《說文解字注》:从日在茻中。會意。茻亦聲。
- ↑ Qiu 2000, p. 155.
- ↑ Sampson & Chen 2013, p. 264.
- ↑ Boltz 1994, pp. 106–110.
- ↑ Sampson & Chen 2013, pp. 266–267.
- ↑ Button 2010.
- ↑ Seeley 1991, p. 203.
- ↑
- ↑ Karlgren 1968, p. 1.
- ↑ Norman 1988, p. 69.
- ↑ Baxter 1992, pp. 771, 772.
- ↑ Sampson & Chen 2013, pp. 260–261.
- ↑ Qiu 2000, ch. 6.3.
- This page draws heavily on the French Wikipedia page Classification des sinogrammes, retrieved 12 April 2005.
- Baxter, William H. (1992), A Handbook of Old Chinese Phonology, Berlin: Mouton de Gruyter, ISBN 978-3-11-012324-1.
- Boltz, William G. (1994), The origin and early development of the Chinese writing system, New Haven: American Oriental Society, ISBN 978-0-940490-78-9.
- Button, Christopher (2010), Phonetic Ambiguity in the Chinese Script: A Palaeographical and Phonological Analysis, Munich: Lincom Europa, ISBN 978-3-89586-632-6.
- DeFrancis, John (1984), The Chinese Language: Fact and Fantasy, Honolulu: University of Hawaii Press, ISBN 978-0-8248-1068-9.
- —— (1989), Visible Speech: The Diverse Oneness of Writing Systems, Honolulu: University of Hawaii Press, ISBN 978-0-8248-1207-2.
- Hansen, Chad (1993), "Chinese Ideographs and Western Ideas", The Journal of Asian Studies, 52 (2): 373–399, doi:10.2307/2059652, JSTOR 2059652.
- Karlgren, Bernhard (1968), Loan Characters in Pre-Han Texts, Stockholm: Museum of Far Eastern Antiquities.
- Norman, Jerry (1988), Chinese, Cambridge: Cambridge University Press, ISBN 978-0-521-29653-3.
- Qiu, Xigui (2000), Chinese writing, trans. by Gilbert L. Mattos and Jerry Norman, Berkeley: Society for the Study of Early China and The Institute of East Asian Studies, University of California, ISBN 978-1-55729-071-7. (English translation of Wénzìxué Gàiyào 文字學概要, Shangwu, 1988.)
- Sampson, Geoffrey; Chen, Zhiqun (2013), "The reality of compound ideographs" (PDF), Journal of Chinese Linguistics, 41: 255–272.
- Seeley, Christopher (1991), A History of Writing in Japan, BRILL, ISBN 978-90-04-09081-1.
- Wang, Hongyuan 王宏源 (1993), The Origins of Chinese characters, Beijing: Sinolingua, ISBN 978-7-80052-243-7.
- Wilkinson, Endymion (2013), Chinese History: A New Manual, Harvard-Yenching Institute Monograph Series, Cambridge, MA: Harvard University Asia Center, ISBN 978-0-674-06715-8.
- Woon, Wee Lee 雲惟利 (1987), 漢字的原始和演變 [Chinese Writing: Its Origin and Evolution], Macau: University of Macau.
Further reading
- Tong Dai; Tʻung Tai (1881). The six scripts. AMOY: Printed by A. A. Marcal. p. 61. Retrieved 10 February 2012.(Harvard University)(Translated by Lionel Charles Hopkins) (Note:Tond Dai and T'ung Tai are the same person, he was counted as two authors on google books)
- Tong Dai; Walter Perceval Yetts (1954). The six scripts: or, The principles of Chinese writing. CUP Archive. p. 84. Retrieved 10 February 2012.(Translated by Lionel Charles Hopkins, Walter Perceval Yetts )
- Tai Tung; L. C. Hopkins (2012). The Six Scripts Or the Principles of Chinese Writing by Tai Tung: A Translation by L. C. Hopkins, with a Memoir of the Translator by W. Perceval Yetts. Cambridge University Press. p. 114. ISBN 1-107-60515-6. Retrieved 10 February 2012.(Translated by L. C. Hopkins )
External links
| Wikibooks has a book on the topic of: Written Chinese/Lesson 1 |
- Images of the Different character classifications
- The Silver Horde: Mongol Scripts
- Image of pictograms in Hanzi