Byte
The byte (/ˈbaɪt/) is a unit of digital information that most commonly consists of eight bits. Historically, the byte (symbol B) was the number of bits used to encode a single character of text in a computer[1][2] and for this reason it is the smallest addressable unit of memory in many computer architectures. The size of the byte has historically been hardware dependent and no definitive standards existed that mandated the size. The de facto standard of eight bits is a convenient power of two permitting the values 0 through 255 for one byte. The international standard IEC 80000-13 codified this common meaning. Many types of applications use information representable in eight or fewer bits and processor designers optimize for this common usage. The popularity of major commercial computing architectures has aided in the ubiquitous acceptance of the 8-bit size.[3]
History
The term byte was coined by Werner Buchholz in July 1956, during the early design phase for the IBM Stretch[4][5] computer, which had addressing to the bit and variable field length (VFL) instructions with a byte size encoded in the instruction. It is a deliberate respelling of bite to avoid accidental mutation to bit.[1]
Early computers used a variety of four-bit binary coded decimal (BCD) representations and the six-bit codes for printable graphic patterns common in the U.S. Army (Fieldata) and Navy. These representations included alphanumeric characters and special graphical symbols. These sets were expanded in 1963 to seven bits of coding, called the American Standard Code for Information Interchange (ASCII) as the Federal Information Processing Standard, which replaced the incompatible teleprinter codes in use by different branches of the U.S. government and universities during the 1960s. ASCII included the distinction of upper- and lowercase alphabets and a set of control characters to facilitate the transmission of written language as well as printing device functions, such as page advance and line feed, and the physical or logical control of data flow over the transmission media. During the early 1960s, while also active in ASCII standardization, IBM simultaneously introduced in its product line of System/360 the eight-bit Extended Binary Coded Decimal Interchange Code (EBCDIC), an expansion of their six-bit binary-coded decimal (BCDIC) representation used in earlier card punches.[6] The prominence of the System/360 led to the ubiquitous adoption of the eight-bit storage size, while in detail the EBCDIC and ASCII encoding schemes are different.
In the early 1960s, AT&T introduced digital telephony first on long-distance trunk lines. These used the eight-bit µ-law encoding. This large investment promised to reduce transmission costs for eight-bit data.
The development of eight-bit microprocessors in the 1970s popularized this storage size. Microprocessors such as the Intel 8008, the direct predecessor of the 8080 and the 8086, used in early personal computers, could also perform a small number of operations on the four-bit pairs in a byte, such as the decimal-add-adjust (DAA) instruction. A four-bit quantity is often called a nibble, also nybble, which is conveniently represented by a single hexadecimal digit.
The term octet is used to unambiguously specify a size of eight bits. It is used extensively in protocol definitions.
Historically, the term octad or octade was used to denote eight bits as well at least in Western Europe;[7][8] however, this usage is no longer common. The exact origin of the term is unclear, but it can be found in British, Dutch, and German sources of the 1960s and 1970s, and throughout the documentation of Philips mainframe computers.
Unit symbol
| Prefixes for multiples of bits (bit) or bytes (B) | |||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
|
| ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
The unit symbol for the byte is specified in IEC 80000-13, IEEE 1541 and the Metric Interchange Format[9] as the upper-case character B. The unit symbol kB is commonly used for kilobyte, but may be confused with the still often-used abbreviation of kb for kilobit. IEEE 1541 specifies the lower case character b as the symbol for bit; however, IEC 80000-13 and Metric-Interchange-Format specify the symbol as bit, e.g., Mbit (megabit), providing disambiguation from B for byte.
A byte is symbolically marked as the upper-case B by the IEC and IEEE[9] in contrast to the bit, whose IEEE symbol is a lower-case b (whereas IEC distinguishes further by using the symbol 'bit'). Internationally, the unit octet, symbol o, explicitly denotes a sequence of eight bits, eliminating the ambiguity of the byte.[10] The usage of the term octad(e) for eight bits is no longer common.[7][8]
There is an ambiguity in the International System of Quantities, where the unit represented by the B symbol can be either the bel or the byte. In that system, the unit represented (bel) quantifies logarithmic power ratios; in contrast to the byte represented in the IEC specification. However, there is little danger of confusion, because the unprefixed bel is a rarely used unit. It is used primarily in its decadic fraction, the decibel (dB), for signal strength and sound pressure level measurements. The decibyte (represented value one tenth of a byte) shares the same d- fractional prefix for one tenth of the unit, but by comparison would only be used in derived units – for example the time-derived transmission rate.
The lowercase letter o for octet is defined as the symbol for octet in IEC 80000-13 and is commonly used in languages such as French[11] and Romanian, and is also combined with metric prefixes for multiples, for example ko and Mo.
Unit multiples
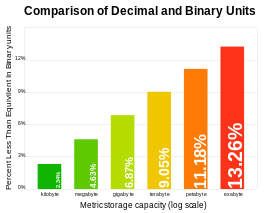
Despite standardization efforts, ambiguity still exists in the meanings of the SI (or metric) prefixes used with the unit byte, especially concerning the prefixes kilo (k or K), mega (M), and giga (G). Computer memory has a binary architecture in which multiples are expressed in powers of 2. In some fields of the software and computer hardware industries a binary prefix is used for bytes and bits, while producers of computer storage devices practice adherence to decimal SI multiples. For example, a computer disk drive capacity of 100 gigabytes is specified when the disk contains 100 billion bytes (93 gibibytes) of storage space.
While the numerical difference between the decimal and binary interpretations is relatively small for the prefixes kilo and mega, it grows to over 20% for prefix yotta. The linear-log graph at right illustrates the difference versus storage size up to an exabyte.
Common uses
Many programming languages defined the data type byte.
The C and C++ programming languages define byte as an "addressable unit of data storage large enough to hold any member of the basic character set of the execution environment" (clause 3.6 of the C standard). The C standard requires that the integral data type unsigned char must hold at least 256 different values, and is represented by at least eight bits (clause 5.2.4.2.1). Various implementations of C and C++ reserve 8, 9, 16, 32, or 36 bits for the storage of a byte.[12][13][lower-alpha 1] In addition, the C and C++ standards require that there are no "gaps" between two bytes. This means every bit in memory is part of a byte.[14]
Java's primitive byte data type is always defined as consisting of 8 bits and being a signed data type, holding values from −128 to 127.
.NET programming languages, such as C#, define both an unsigned byte and a signed sbyte, holding values from 0 to 255, and −128 to 127, respectively.
In data transmission systems, the byte is defined as a contiguous sequence of bits in a serial data stream, representing is the smallest distinguished unit of data. A transmission unit might include start bits, stop bits, or parity bits, and thus could vary from 7 to 12 bits to contain a single 7-bit ASCII code.[15]
See also
- Word (computer architecture)
- Data hierarchy
- JBOB, Just a Bunch Of Bytes
- Primitive data type
- Tryte
- Qubyte (quantum byte)
Notes
References
- 1 2 Bemer, RW; Buchholz, Werner (1962), "4, Natural Data Units", in Buchholz, Werner, Planning a Computer System – Project Stretch (PDF), pp. 39–40
- ↑ Bemer, RW (1959), "A proposal for a generalized card code of 256 characters", Communications of the ACM, 2 (9): 19–23, doi:10.1145/368424.368435
- ↑ "Computer History Museum - Exhibits - Internet History - 1964". Computer History Museum.
- ↑ Werner Buchholz (July 1956). "Timeline of the IBM Stretch/Harvest era (1956–1961)". Computer History.
- ↑ "byte definition".
- ↑ "IBM confirms the use of EBCDIC in their mainframes as a default practice". IBM. 2008. Retrieved 2008-06-16.
- 1 2 Williams, R. H. (1969-01-01). "British Commercial Computer Digest: Pergamon Computer Data Series". Pergamon Press. ISBN 1483122107. 978-1483122106. Retrieved 2015-08-03.
- 1 2 "Philips - Philips Data Systems' product range - April 1971" (PDF). Philips. 1971. Retrieved 2015-08-03.
- 1 2 Metric-Interchange-Format
- ↑ "The TCP/IP Guide - Binary Information and Representation".
- ↑ "When is a kilobyte a kibibyte? And an MB an MiB?". The International System of Units and the IEC. International Electrotechnical Commission. Retrieved August 30, 2010.)
- ↑ Marshall Cline. "I could imagine a machine with 9-bit bytes. But surely not 16-bit bytes or 32-bit bytes, right?"
- ↑ Klein, Jack (2008), Integer Types In C and C++, archived from the original on 2010-03-27, retrieved 2015-06-18
- ↑ Marshall Cline. "C++ FAQ: the rules about bytes, chars, and characters".
- ↑ Northwestern University. "External Interfaces/API"