Backpropagation through time
Backpropagation through time (BPTT) is a gradient-based technique for training certain types of recurrent neural networks. It can be used to train Elman networks. The algorithm was independently derived by numerous researchers[1][2][3]
Algorithm
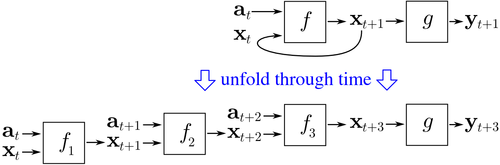
The training data for BPTT should be an ordered sequence of input-output pairs, . An initial value must be specified for . Typically, a vector of all zeros is used for this purpose.


BPTT begins by unfolding a recurrent neural network through time as shown in this figure. This recurrent neural network contains two feed-forward neural networks, f and g. When the network is unfolded through time, the unfolded network contains k instances of f and one instance of g. In the example shown, the network has been unfolded to a depth of k=3.
Training then proceeds in a manner similar to training a feed-forward neural network with backpropagation, except that each epoch must run through the observations, , in sequential order. Each training pattern consists of . (All of the actions for k time-steps are needed because the unfolded network contains inputs at each unfolded level.) Typically, backpropagation is applied in an online manner to update the weights as each training pattern is presented.


After each pattern is presented, and the weights have been updated, the weights in each instance of f () are averaged together so that they all have the same weights. Also, is calculated as , which provides the information necessary so that the algorithm can move on to the next time-step, t+1.



Pseudo-code
Pseudo-code for BPTT:
Back_Propagation_Through_Time(a, y) // a[t] is the input at time t. y[t] is the output
Unfold the network to contain k instances of f
do until stopping criteria is met:
x = the zero-magnitude vector;// x is the current context
for t from 0 to n - k // t is time. n is the length of the training sequence
Set the network inputs to x, a[t], a[t+1], ..., a[t+k-1]
p = forward-propagate the inputs over the whole unfolded network
e = y[t+k] - p; // error = target - prediction
Back-propagate the error, e, back across the whole unfolded network
Update all the weights in the network
Average the weights in each instance of f together, so that each f is identical
x = f(x, a[t]); // compute the context for the next time-step
Advantages
BPTT tends to be significantly faster for training recurrent neural networks than general-purpose optimization techniques such as evolutionary optimization.[4]
Disadvantages
BPTT has difficulty with local optima. With recurrent neural networks, local optima is a much more significant problem than it is with feed-forward neural networks.[5] The recurrent feedback in such networks tends to create chaotic responses in the error surface which cause local optima to occur frequently, and in very poor locations on the error surface.
See also
References
- ↑ Mozer, M. C. (1995). Y. Chauvin; D. Rumelhart, eds. A Focused Backpropagation Algorithm for Temporal Pattern Recognition. Hillsdale, NJ: Lawrence Erlbaum Associates. pp. 137–169.
- ↑ Robinson, A. J. & Fallside, F. (1987). The utility driven dynamic error propagation network (Technical report). Cambridge University, Engineering Department. CUED/F-INFENG/TR.1.
- ↑ Paul J. Werbos (1988). "Generalization of backpropagation with application to a recurrent gas market model". Neural Networks. 1 (4): 339–356. doi:10.1016/0893-6080(88)90007-X.
- ↑ Jonas Sjöberg and Qinghua Zhang and Lennart Ljung and Albert Benveniste and Bernard Deylon and Pierre-yves Glorennec and Hakan Hjalmarsson and Anatoli Juditsky (1995). "Nonlinear Black-Box Modeling in System Identification: a Unified Overview". Automatica. 31: 1691–1724. doi:10.1016/0005-1098(95)00120-8.
- ↑ M.P. Cuéllar and M. Delgado and M.C. Pegalajar (2006). "An Application of Non-linear Programming to Train Recurrent Neural Networks in Time Series Prediction Problems". Enterprise Information Systems VII. Springer Netherlands: 95–102. doi:10.1007/978-1-4020-5347-4\_11. ISBN 978-1-4020-5323-8.