Asymmetric Numeral Systems
Asymmetric Numeral Systems (ANS) [1] is a family of entropy coding methods used in data compression since 2014[2] for example in the Facebook Zstandard compressor[3] and Apple LZFSE compressor,[4] due to improved performance compared to the previously used methods: it allows combination of the compression ratio of arithmetic coding (uses nearly accurate probability distribution), with a processing cost similar to Huffman coding (tANS variant constructs finite state machine to operate on large alphabet without using multiplication).
The basic concept is to directly encode information into a single natural number , increased approximately times while adding information from symbol of probability . For the encoding rule, the set of natural numbers is split into disjoint subsets corresponding to different symbols - like into even and odd numbers, but with densities corresponding to the probability distribution of symbols to encode. Then to add information from symbol into information already stored in the current number , we go to number being position of -th appearances from -th subset.





There are alternative ways to apply it in practice - direct mathematical formulas for encoding and decoding steps (uABS and rANS variants), or one can put the entire behavior into a table (tANS variant). Renormalization is used to prevent going to infinity - transferring accumulated bits to or from the bitstream.
Basic concepts

Imagine there is some information stored in a natural number , for example as bit sequence of its binary expansion. To add information from a binary variable , we can use coding function , which shifts all bits one position up, and place the new bit in the least significant position. Now decoding function allows to retrieve the previous and this added bit: . We can start with initial state, then use the function on the successive bits of a finite bit sequence to obtain a final number storing this entire sequence. Then using function multiple times until allows to retrieve the bit sequence in reversed order.






The above procedure is optimal for uniform (symmetric) probability distribution of symbols . ANS generalize it to make it optimal for any chosen (asymmetric) probability distribution of symbols: . While in the above example was choosing between even and odd , in ANS this even/odd division of natural numbers is replaced with division into subsets having densities corresponding to the assumed probability distribution : up to position , there is approximately occurrences of symbol .





The coding function returns the -th appearance from such subset corresponding to symbol . The density assumption is equivalent to condition . Assuming that a natural number contains bits information, . Hence the symbol of probability is encoded as containing bits of information as it is required from entropy coders.





Uniform binary variant (uABS)
Let us start with binary alphabet and probability distribution . Up to position we want approximately analogues of odd numbers (for ). We can choose this number of appearances as , getting . This is called uABS variant and leads to the following decoding and encoding functions:[5]





Decoding:
s = ceil((x+1)*p) - ceil(x*p) // 0 if fract(x*p) < 1-p, else 1
if s = 0 then new_x = x - ceil(x*p) // D(x) = (new_x, 0)
if s = 1 then new_x = ceil(x*p) // D(x) = (new_x, 1)
Encoding:
if s = 0 then new_x = ceil((x+1)/(1-p)) - 1 // C(x,0) = new_x
if s = 1 then new_x = floor(x/p) // C(x,1) = new_x
For it becomes standard binary system (with switched 0 and 1), for a different it becomes optimal for this given probability distribution. For example, for these formulas lead to table for small values of :


| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 | 20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | ||||||||
| 0 | 1 | 2 | 3 | 4 | 5 | 6 |

Symbol corresponds to subset of natural numbers of density , which in this case are positions . As , these positions increase by 3 or 4. Because here, the pattern of symbols repeats every 10 positions.



The can be found by taking row corresponding to a given symbol , and take given in this row. Then top row provides . For example, from the middle to top row.

Imagine we would like to encode '0100' sequence starting from . First takes us to , then to , then to , then to . By using decoding function on this final , we can retrieve the symbol sequence. Using the table for this purpose, in first row determines column, then nonempty row and the written value determine correspondingly and .





Range variants (rANS) and streaming
Range variant also uses arithmetic formulas, but allows to operate on large alphabet. Intuitively, it divides the set of natural numbers into size ranges, and split each of them in identical way into subranges of proportions given by the assumed probability distribution.

We start with quanization of probability distribution to denominator, where is chosen (usually 8-12 bits): for some natural numbers (sizes of subranges).

![{\displaystyle p_{s}\approx f[s]/2^{n}}](../I/m/40126868e68a77b26573dad74920a14de1704362.svg)
![{\displaystyle f[s]}](../I/m/ec0ec2bde4d14b5c3f96722064d2a437b3a60943.svg)
Denote , cumulative distribution function: .

![{\displaystyle \operatorname {CDF} [s]=\sum _{i<s}f[i]=f[0]+\ldots +f[s-1]}](../I/m/514ee982ed9bad69aedaf8e11863a05db8cb8008.svg)
For denote function (usually tabled)
![{\displaystyle y\in [0,2^{n}-1]}](../I/m/44d7b69a00a701d2451c012089a30f0c8c843d8f.svg)
symbol(y) = s such that CDF[s] <= y < CDF[s+1] .
Now coding function is:
C(x,s) = floor(x / f[s]) << n) + (x % f[s]) + CDF[s]
Decoding: s = symbol(x & mask)
D(x) = (f[s] * (x >> n) + (x & mask ) - CDF[s], s)
This way we can encode a sequence of symbols into a large natural number . To avoid using large number arithmetic, in practice stream variants are used: which enforce by renormalization: sending the least significant bits of to or from the bitstream (usually and are powers of 2).
![{\displaystyle x\in [L,b\cdot L-1]}](../I/m/34ee0db0314040ff0124481746ca4f8293998569.svg)


In rANS variant is for example 32 bit. For 16 bit renormalization, , decoder refills the least significant bits from the bitstream when needed:
![{\displaystyle x\in [2^{16},2^{32}-1]}](../I/m/eb418defe57810e11674537816edb2f35ee00283.svg)
if(x < (1 << 16)) x = (x << 16) + read16bits()
Tabled variant (tANS)
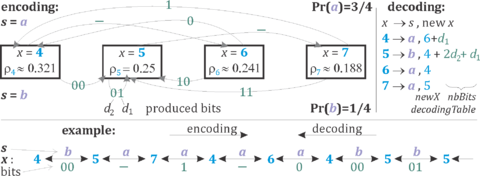
tANS variant puts the entire behavior (including renormalization) for into a table, getting finite state machine avoiding the need of multiplication.
![{\displaystyle x\in [L,2L-1]}](../I/m/acc59ff382cc526d689cc5164768d32a1b100eda.svg)
Finally step of decoding loop can be written as:
t = decodingTable(x);
x = t.newX + readBits(t.nbBits); //state transition
writeSymbol(t.symbol); //decoded symbol
Step of encoding loop:
s = ReadSymbol();
nbBits = (x + ns[s]) >> r; // # of bits for renormalization
writeBits(x, nbBits); // send youngest bits to bitstream
x = encodingTable[start[s] + (x >> nbBits)];
A specific tANS coding is determined by assigning a symbol to every position, their number of appearances should be proportional to the assumed probabilities. For example one could choose "abdacdac" assignment for Pr(a)=3/8, Pr(b)=1/8, Pr(c)=2/8, Pr(d)=2/8 probability distribution. If symbols are assigned in ranges of lengths being powers of 2, we would get Huffman coding. For example a->0, b->100, c->101, d->11 prefix code would be obtained for tANS with "aaaabcdd" symbol assignment.
![{\displaystyle [L,2L-1]}](../I/m/096f88273992ec8a67b4368c8925357f2d625d23.svg)
Remarks
As for Huffman coding, modifying the probability distribution of tANS is costly, hence they are used in static situations, usually with some Lempel–Ziv scheme (ZSTD, LZFSE). In this case, the file is divided into blocks and static probability distribution for each block is stored in its header.
In contrast, rANS is usually used as faster replacement for range coding. It requires multiplication, but is more memory efficient and is appropriate for dynamically adapting probability distributions.
Encoding and decoding of ANS are performed in opposite directions. This inconvenience is usually resolved by encoding in backward direction, thanks of it decoding can made forward. For context-dependence, like Markov model, the encoder needs to use context from the perspective of decoder. For adaptivity, the encoder should first go forward to find probabilities which will be used by decoder and store them in a buffer, then encode in backward direction using the found probabilities.
The final state of encoding is required to start decoding, hence it needs to be stored in the compressed file. This cost can be compensated by storing some information in the initial state of encoder.
See also
- Entropy encoding
- Huffman coding
- Arithmetic coding
- Range coding
- Zstandard Facebook compressor
- LZFSE Apple compressor
References
- ↑ J. Duda, K. Tahboub, N. J. Gadil, E. J. Delp, The use of asymmetric numeral systems as an accurate replacement for Huffman coding, Picture Coding Symposium, 2015.
- ↑ List of compressors using ANS, implementations and other materials
- ↑ Smaller and faster data compression with Zstandard, Facebook, August 2016
- ↑ Apple Open-Sources its New Compression Algorithm LZFSE, InfoQ, July 2016
- ↑ Data Compression Explained, Matt Mahoney
External links
- High throughput hardware architectures for asymmetric numeral systems entropy coding S. M. Najmabadi, Z. Wang, Y. Baroud, S. Simon, ISPA 2015
- https://github.com/Cyan4973/FiniteStateEntropy Finite state entropy (FSE) implementation of tANS by Yann Collet
- https://github.com/rygorous/ryg_rans Implementation of rANS by Fabian Giesen
- https://github.com/jkbonfield/rans_static Fast implementation of rANS and aritmetic coding by James K. Bonfield
- https://github.com/facebook/zstd/ Facebook Zstandard compressor by Yann Collet (author of LZ4)
- https://github.com/lzfse/lzfse LZFSE compressor (LZ+FSE) of Apple Inc.
- CRAM 3.0 DNA compressor (order 1 rANS) (part of SAMtools) by European Bioinformatics Institute
- https://chromium-review.googlesource.com/#/c/318743 implementation for Google VP10
- https://chromium-review.googlesource.com/#/c/338781/ implementation for Google WebP
- https://aomedia.googlesource.com/aom/+/master/aom_dsp implementation of Alliance for Open Media
- http://demonstrations.wolfram.com/DataCompressionUsingAsymmetricNumeralSystems/ Wolfram Demonstrations Project
- http://gamma.cs.unc.edu/GST/ GST: GPU-decodable Supercompressed Textures
- Understanding compression book by A. Haecky, C. McAnlis
Data compression methods | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Lossless |
| ||||||||||
| Audio |
| ||||||||||
| Image |
| ||||||||||
| Video |
| ||||||||||
| Theory | |||||||||||
| |||||||||||